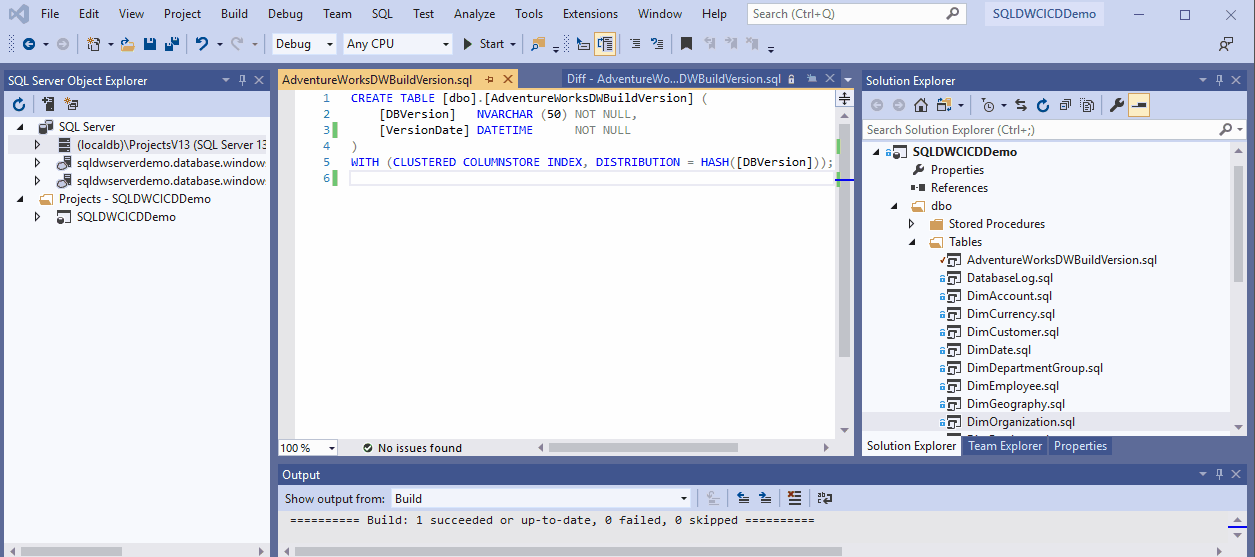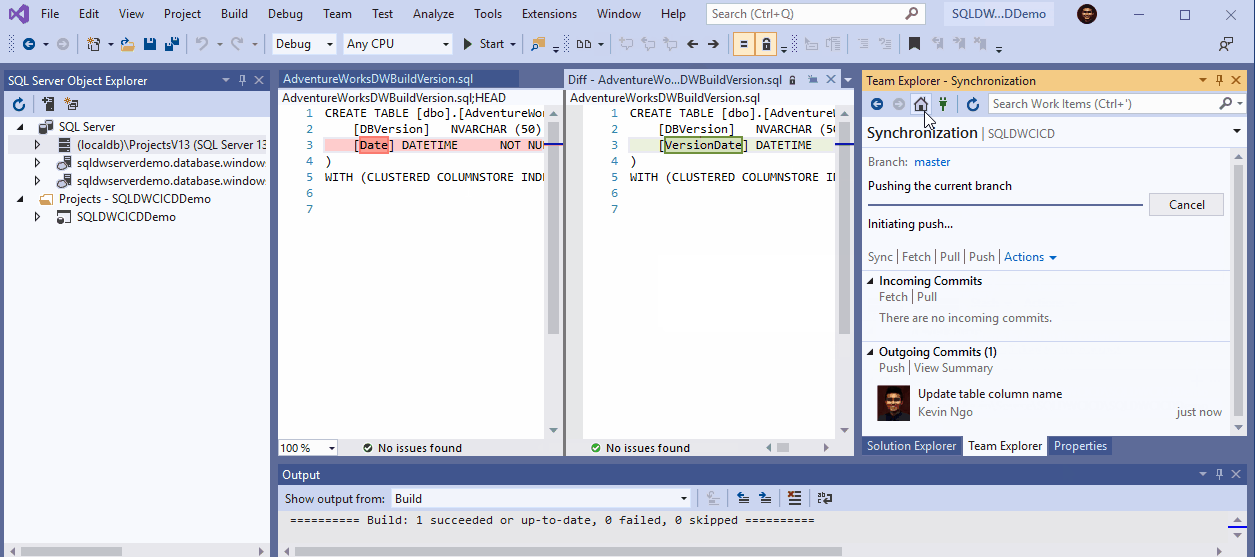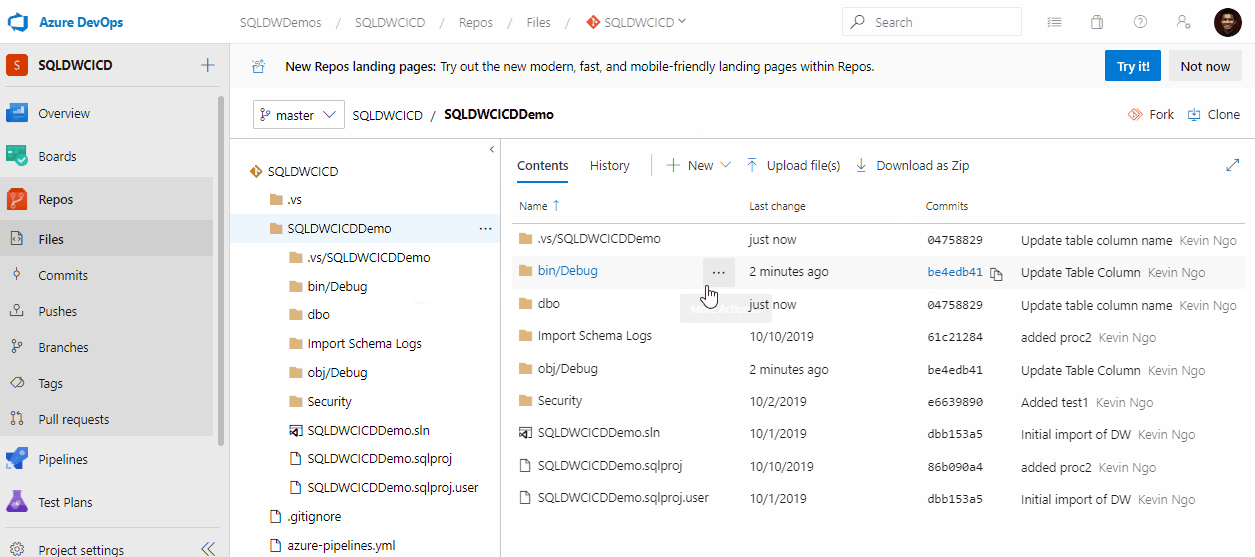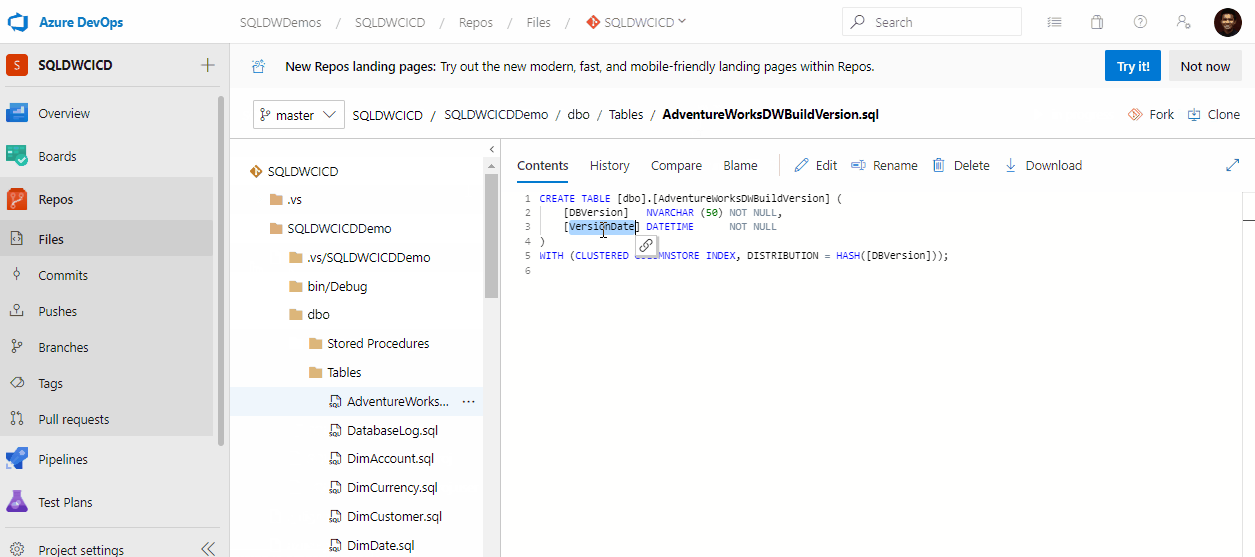
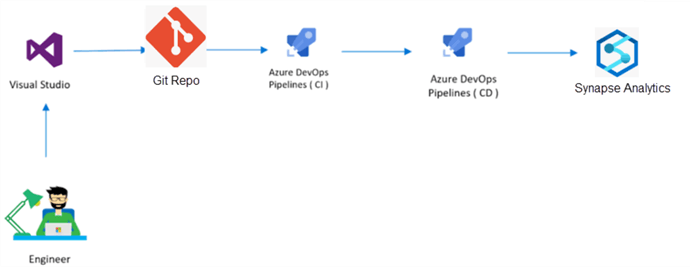
Hemos tomado 5 principios de ingeniería del caos de este post de Toward Science aplicados a la gestión de datos.
El “#Chaos #Engineering” o “Ingeniería del Caos” en tecnología es una práctica que consiste en introducir de manera controlada y planificada ciertos niveles de caos en un sistema informático en producción para evaluar su resiliencia y capacidad de recuperación frente a situaciones inesperadas o fallos.
El objetivo del Chaos Engineering es identificar posibles puntos débiles en la arquitectura del sistema y mejorar la calidad del software. Para ello, se realizan pruebas de estrés en condiciones simuladas de fallo y se mide el impacto en el sistema para evaluar cómo este responde a situaciones adversas. De esta manera, se puede mejorar la capacidad de recuperación del sistema ante fallos reales y minimizar el impacto en los usuarios.
Las pruebas de #ChaosEngineering se realizan de forma controlada y planificada para minimizar los posibles impactos en la operativa del sistema en producción. Para ello, se utiliza una metodología basada en la observación, el aprendizaje y la mejora continua del sistema.
Los principios y las lecciones de la ingeniería del caos son un buen lugar para comenzar a definir los contornos de una disciplina de ingeniería del caos de datos. Nuestra primera ley combina dos de las más importantes.
Primera ley: tenga un sesgo para la producción, pero minimice el radio de explosión
Existe una máxima entre los ingenieros de site reliability que resultará cierta para todos los ingenieros de datos que hayan tenido el placer de que la misma consulta SQL arroje dos resultados diferentes en los entornos de producción y ensayo. Es decir, “Nada actúa como producción excepto por producción”.
A eso yo agregaría, “datos de producción también”. Los datos son demasiado creativos y fluidos para que los humanos los anticipen. Los datos sintéticos han recorrido un largo camino, y no me malinterpreten, pueden ser una pieza del rompecabezas, pero es poco probable que simulen casos clave.
Al igual que yo, la mera idea de introducir puntos de falla en los sistemas de producción probablemente le revuelva el estómago. Es aterrador Algunos ingenieros de datos se preguntan con razón: “¿Es esto necesario dentro de una pila de datos moderna donde tantas herramientas abstraen la infraestructura subyacente?”
Me temo que sí. Recuerde, como ilustran la anécdota inicial y los ligamentos rotos de J-Kidd, la elasticidad de la nube no es una panacea.
De hecho, es esa abstracción y opacidad, junto con los múltiples puntos de integración, lo que hace que sea tan importante realizar pruebas de estrés en una pila de datos moderna. Una base de datos local puede ser más limitante, pero los equipos de datos tienden a comprender sus umbrales, ya que los alcanzan con mayor frecuencia durante las operaciones diarias.
Dejemos atrás las objeciones filosóficas por el momento y sumerjámonos en lo práctico. Los datos son diferentes. Introducir datos falsos en un sistema no será útil porque la entrada cambia la salida. También se va a poner muy desordenado.
Ahí es donde entra en juego la segunda parte de la ley: minimizar el radio de explosión. Existe un espectro de caos y herramientas que se pueden utilizar:
- En palabras solamente, “digamos que esto falló, ¿qué haríamos?”
- Datos sintéticos en producción
- Técnicas como diferencia de datos que le permiten probar fragmentos de código SQL en datos de producción
- Las soluciones como LakeFS le permiten hacer esto a mayor escala mediante la creación de “ramas de caos” o instantáneas completas de su entorno de producción, donde puede usar datos de producción pero con un aislamiento total.
- Hágalo en producción y practique sus habilidades de relleno. Después de todo, nada actúa como producción, sino producción.
Comenzar con escenarios menos caóticos es probablemente una buena idea y lo ayudará a comprender cómo minimizar el radio de explosión en la producción.
Profundizar en los incidentes de producción reales también es un excelente lugar para comenzar. ¿Todos realmente entienden lo que sucedió exactamente? Los incidentes de producción son experimentos de caos por los que ya pagó, así que asegúrese de aprovecharlos al máximo.
Mitigar el radio de explosión también puede incluir estrategias como la copia de seguridad de los sistemas aplicables o contar con una solución de monitoreo de calidad de datos u observabilidad de datos para ayudar con la detección y resolución de incidentes de datos.
Segunda Ley: Comprende que nunca es un momento perfecto (dentro de lo razonable)
Otro principio de ingeniería del caos se sostiene para observar y comprender el “comportamiento de estado estable”.
Hay sabiduría en este principio, pero también es importante comprender que el campo de la ingeniería de datos no está listo para medirse con el estándar de “5 9s” o 99,999 % de tiempo de actividad.
Los sistemas de datos están en constante cambio y existe una gama más amplia de “comportamiento de estado estable”. Habrá la tentación de retrasar la introducción del caos hasta que haya alcanzado el punto mítico de “preparación”. Bueno, no puede superar la arquitectura de los datos incorrectos y nadie está preparado para el caos.
El cliché de Silicon Valley de fallar rápido es aplicable aquí. O, parafraseando a Reid Hoffman , si no te avergüenzan los resultados de tu primer evento pre-mortem/simulacro de incendio/caos, lo presentaste demasiado tarde.
La introducción de incidentes de datos falsos mientras se trata de incidentes reales puede parecer una tontería, pero en última instancia, esto puede ayudarlo a salir adelante al comprender mejor dónde ha estado poniendo curitas en problemas más importantes que pueden necesitar ser refactorizados.
Tercera Ley: Formular hipótesis e identificar variables a nivel de sistema, código y datos
La #ingenieriadelcaos fomenta la formación de hipótesis sobre cómo reaccionarán los sistemas para comprender qué umbrales monitorear. También fomenta el aprovechamiento o la imitación de incidentes pasados del mundo real o incidentes probables.
Profundizaremos en los detalles de esto en la siguiente sección, pero la modificación importante aquí es garantizar que abarquen el sistema, el código y los niveles de datos. Las variables en cada nivel pueden crear incidentes de datos, algunos ejemplos rápidos:
- Sistema: no tenía los permisos correctos establecidos en su almacén de datos.
- Código: Una mala setencia de left JOIN.
- Datos : un tercero le envió columnas basura con un montón de NULLS.
Simular mayores niveles de tráfico y apagar los servidores afecta los sistemas de datos, y esas son pruebas importantes, pero no descuide algunas de las formas más únicas y divertidas en que los sistemas de datos pueden fallar.
Cuarta Ley: Todos en una habitación (o al menos llamada Zoom)
Esta ley se basa en la experiencia de mi colega, el ingeniero de confiabilidad del sitio y experto en caos Tim Tischler .
“La ingeniería del caos se trata tanto de personas como de sistemas. Evolucionan juntos y no se pueden separar. La mitad del valor de estos ejercicios proviene de poner a todos los ingenieros en una habitación y preguntar, ‘¿qué sucede si hacemos X o hacemos Y?’ Tiene la garantía de obtener respuestas diferentes. Una vez que simulas el evento y ves el resultado, ahora los mapas mentales de todos están alineados. Eso es increíblemente valioso”, dijo.
Además, la interdependencia de los sistemas de datos y las responsabilidades crea líneas borrosas de propiedad, incluso en los equipos mejor dirigidos. Las rupturas a menudo ocurren, y se pasan por alto, en esas superposiciones y brechas en la responsabilidad donde el ingeniero de datos, el ingeniero analítico y el analista de datos se señalan el uno al otro.
En muchas organizaciones, los ingenieros de productos que crean los datos y los ingenieros de datos que los gestionan están separados y aislados por estructuras de equipo. También suelen tener diferentes herramientas y modelos del mismo sistema y datos. Siéntase libre de atraer también a estos ingenieros de productos, especialmente cuando los datos se han generado a partir de sistemas construidos internamente.
Una buena gestión y clasificación de incidentes a menudo puede involucrar a varios equipos y tener a todos en una habitación puede hacer que el ejercicio sea más productivo.
También agregaré por experiencia personal que estos ejercicios pueden ser divertidos (de la misma manera extraña, poner todas tus fichas en rojo es divertido). Animo a los equipos de datos a que consideren un simulacro de incendio de ingeniería de datos del caos o un evento pre-mortem en el próximo lugar externo. Es un ejercicio de vinculación de equipo mucho más práctico que salir de una sala de escape.
Quinta Ley: Por el momento, absténgase de la automatización
Los programas de ingeniería del caos verdaderamente maduros como Simian Army de Netflix están automatizados e incluso no programados. Si bien esto puede crear una simulación más precisa, la realidad es que las herramientas automatizadas no existen actualmente para la ingeniería de datos. Si lo hicieran, no estoy seguro de si sería lo suficientemente valiente como para usarlos.
Hasta este punto, uno de los ingenieros de caos originales de Netflix ha descrito cómo no siempre usaron la automatización, ya que el caos podría crear más problemas de los que podrían solucionar (especialmente en colaboración con quienes ejecutan el sistema) en un período de tiempo razonable.
Dada la evolución actual de la confiabilidad de la ingeniería de datos y el mayor potencial para un radio de explosión no intencionalmente grande, recomendaría que los equipos de datos se inclinen más hacia eventos programados y cuidadosamente administrados.
Resumen
Para aplicar la ingeniería del caos en la gestión de datos, se pueden seguir algunos principios, como tener un sesgo para la producción y minimizar el radio de explosión. Es importante entender que los datos son diferentes y que introducir datos falsos en un sistema no será útil. Por eso, se pueden utilizar herramientas como la diferencia de datos o soluciones como LakeFS, que permiten crear ramas de caos o instantáneas completas del entorno de producción para realizar pruebas con datos reales.
También es importante comprender que nunca habrá un momento perfecto para realizar pruebas de ingeniería del caos y que es necesario tener en cuenta estrategias de mitigación del riesgo, como la copia de seguridad de los sistemas o el monitoreo de calidad de datos. Al profundizar en los incidentes de producción reales, se pueden obtener valiosas lecciones sobre cómo mejorar la resiliencia del sistema.
En resumen, la ingeniería del caos puede ser una herramienta útil para mejorar la calidad y resiliencia del software en la gestión de datos, siempre y cuando se realicen de manera planificada y controlada.





 de datos, aplicaciones empresariales y servicios web. Estos componentes se pueden personalizar y combinar para adaptarse a las necesidades específicas de cada proyecto.
de datos, aplicaciones empresariales y servicios web. Estos componentes se pueden personalizar y combinar para adaptarse a las necesidades específicas de cada proyecto.