Quienes nos siguen dirán, ¿Otro nuevo Ops en familia? Y si, tenemos que contarles sobre #MLOPS.
Repasemos. #DevOps conjuga la unión de los equipos de Desarrollo con Operaciones. #DataOps va acerca de la integración de datos en pos de soluciones analíticas. #GitOps nos ayuda a con el despliegue continuo sobre plataformas de contenedores. Y ahora nos toca describir MLOPS.
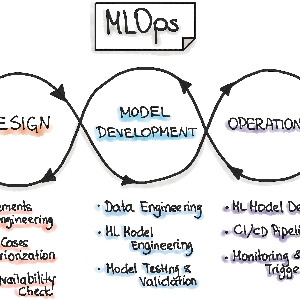
¿Que es MLOPS?
El nombre viene de la conjugación de Machine Learning y Operaciones. Y su filosofía gira en torno a lo mismo que sus familiares *Ops, la de generar un espacio colaborativo, en este caso entre Científicos de Datos y Operaciones. Es importante destacar que hace un tiempo se puso de moda el termino #AIOPS, pero esta mas orientado a una implementación de Inteligencia Artificial a las operaciones de TI, de manera que podria ser confundible con MLOPS.
Empecemos a descubrir MLOPS.

¿Que soluciona MLOPS?
MLOps es un descendiente directo de DevOps, y continuando con el éxito busca resolver la integración de los equipos de operaciones (en este caso quienes operan los datos) con aquellos que requieren de esa data para generar informacion de valor.
MLOps incorpora al juego a los científicos de datos, quienes requieren obtener conjuntos de datos de manera automatizada desde donde poder desarrollar sus modelos analíticos.
¿MLOPS requiere de un Pipeline?
Correcto, MLOPS tiene su propio concepto de Pipeline, solo que el CI/CD, esta orientado a integraciones de datos, y junto con ello, capacidades de gobernanza, transparencia y protección de la informacion.
- En CI ademas de probar y validar código y componentes, se deben validar datos, esquemas y modelos.
- En CD ademas de desplegar un paquete, debe implementar todo un servicio de manera automática.
En resumidas fases podriamos mencionar que MLOPS requiere de 4 pasos fundamentales:
- Ingestar datos hacia un almacenamiento.
- Procesar los datos almacenados.
- Entregar esos datos para ser entrenados dentro de modelos de #MachineLearning.
- Entregar el output del modelo, dependiendo el caso de negocio requerido.
¿Como comienzo mi camino hacia MLOPS?
Es importante destacar que la comunidad que impulsa MLOPS crece dia a dia. Y ese crecimiento lleva a tener mas opciones que simplifican la adopción de MLOPS. Tanto #AWS, #GCP, #Azure, #IBM y otros proveedores tienen su propio stack tecnológico para hacer frente a una implementación de MLOPS, y como todo, no existe un método único, pero si buenas practicas recomendadas a seguir.
Para empezar, debemos crear una cultura de automatización.
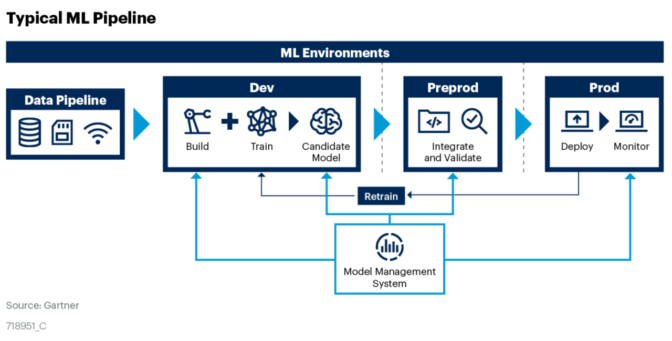
El objetivo de MLOps es automatizar los pasos completos del flujo de trabajo de ML sin intervención manual. A partir de ello debemos dividir las tareas en fases que al final de la historia se ejecuten como un pipeline. Estas tareas son:
- Adquirir los datos desde las fuentes que identifiquemos. Y dentro de esta fase de adquisición vamos a Catalogar los Datos, Ingestarlos a nuestro almacenamiento, Procesarlos para generar nuestra data correcta, y finalmente Entregarlos para su consumo.
- Desarrollar los modelos. En esta fase (quizás la mas importante) un científico de datos generara interacciones con distintos modelos analíticos, validando la data recibida, e identificando la performance de los análisis. En caso de que la data recibida no sea suficiente o de la calidad esperada, el pipeline debe ser reajustado en el paso 1. Pero si los modelos tienen buenos rendimientos se pasara a la siguiente fase.
- Despliegue de los modelos. Como mencionamos anteriormente, si un modelo tiene buenos rendimientos y sus outputs son confiables, esta listo para ser pasado a producción. Tener un modelo productivo permite integrarlo a nuestro software, dejar una API para consultas, alimentar un sistema, etc. Pero atención, el modelo requiere de cuidados, y es por eso que existe una ultima etapa.
- Monitoreo de modelos. Como vamos a tener corriendo todo de forma automatizada, es importante monitorear como es la performance de los modelos. Cualquier desvio en la cantidad y/o calidad de los datos que se reciben pueden alterar el funcionamiento de nuestro desarrollo. Y es por eso que en un modelo MLOPS, vamos a determinar un control para conseguir que nuestro pipeline siempre asegura la entrega de información de valor para el negocio.
Conclusión final
Para ejecutar un proyecto exitoso basado en ciencia de datos es imprescindible implementar MLOps y para ello se debe llevar a cabo una orquestación de las herramientas tecnológicas con las habilidades para integrarlas.
Consultas?
| [popup_anything id=”2076″] |