DataOps, is a methodology that emerged from Agile cultures that seeks to cultivate data management practices and processes to improve the speed and accuracy of the analysis, including access, quality, automation, integration and data models.
DataOps is about aligning the way you manage your data with the goals you have for that data.
It is not bad to remember part of the Manifiesto DataOps:
- People and interactions instead of processes and tools
- Efficient analytics solutions instead of comprehensive documentation
- Collaboration with the consumer instead of contractual negotiations
- Experimentation, interaction and feedback instead of direct extensive design
- Multidisciplinary ownership of operations instead of isolated responsibilities.
We are going to give a clear example of #DataOps applied to the reduction of the customer #turnover rate. You can take advantage of your customers’ data to create a recommendation engine that shows products that are relevant to your customers, which would keep them buying for longer. But that is only possible if your data science team has access to the data they need to build that system and the tools to implement it, and can integrate it with your website, continuously feed new data, monitor performance, etc. For that you need a continuous process that will require you to include information from your engineering, IT and business teams.
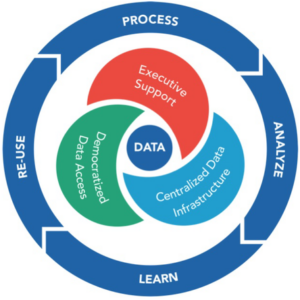
In order to implement solutions that add value, it is necessary to manage healthy data. Better data management leads to better data, and more available. More and better data lead to a better analysis, which translates into better knowledge, business strategies and greater profitability.
DataOps strives to foster collaboration between data scientists, engineers and IT experts so that each team works synchronized to leverage data in the most appropriate way and in less time.
DataOps is one of the many methodologies born from #DevOps. The success of DevOps lies in eliminating the silos of traditional IT: one that manages development work and another that performs operational work. In a DevOps configuration, software implementation is fast and continuous because all the equipment is linked to detect and correct problems as they occur.

DataOps is based on this idea, but applying it throughout the data life cycle. Consequently, DevOps concepts such as CI / CD are now being applied to the data science production process. Data science teams are taking advantage of software version control solutions such as GitHub to track code changes and container technology such as Kubernetes and Openshift to create environments for Analysis and deployment of models. This type of data science and DevOps approach is sometimes called “continuous analysis.”
However. So far the whole theory. But … How do I start implementing DataOps?
This is where you should start:
- #Democratize your data. Remove bureaucratic barriers that prevent access to the organization’s data, any company that strives to be at the forefront needs data sets that are available.
- Take advantage of #opensource platforms and tools. Platforms for data movement, orchestration, integration, performance and more.
- Part of being agile is not wasting time building things that you don’t have to do or reinvent the wheel when the tools your team already knows are open source. Consider your data needs and select your technology stack accordingly.
- Automate, automate, automate. This comes directly from the world of DevOps, it is essential that you #automate the steps that unnecessarily require a great manual effort, such as quality control tests and data analysis pipeline monitoring.
- Enable self-sufficiency with #microservices. For example, giving your data scientists the ability to implement models such as #APIs means that engineers can integrate that code where necessary without #refactoring, resulting in productivity improvements.