Como analizamos en notas anteriores acerca de #GitOps, es importante destacar que su adopción permite gestionar las configuraciones usando Git, y cobra vital importancia cuando hablamos de contenedores dado que se construyende forma declarativa, la configuración de las aplicaciones y sus entornos de implementación son realizadas de manera declarativas (yaml/json).
¿Porque es importante GitOps cuando hablamos de contenedores?
Recordemos que cuando desplegamos un #container basicamente pulleamos código. De esta manera, poder tener un control de versiones permite controlar los despliegues de los #contenedores, por ejemplo para recuperarse de cualquier implementación fallida.
Ademas por medio de herramientas es mucho mas transparente realizar cambios operativos, por ejemplo, solucionar un problema de producción mediante un ‘pull request’ en lugar de realizar cambios en todo el sistema productivo.
Las herramientas GitOps como ArgoCD o FluxCD permiten actuar como una fuente unica de verdad, garantizando los estados de los clusteres a partir del control de las configuraciones.

Usando CI/CD con GitOps
Estas herramientas estan monitoreando los repos con las configuraciones para detectar cambios o imágenes nuevas, de manera de desencadenar automáticamente implementaciones o cambios de configuraciones.
Estas herramientas actuan como CI/CD sin requerir de herramientas adicionales, y el despliegue se encuentra asegurado debido a que funcionan en un formato denominado “atomico y transaccional”, de manera que existen logs que garantizan que las transacciones se realicen correctamente o en caso de fallar no sean aplicados los cambios.
GitOps en la nube
El desarrollo de implementacionees en #kubernetes requiere el despliegue de aplicaciones, clusteres, entornos, etc; y los despliegues en la nube no son una excepción.
Por ese motivo, comprender como GitOps se integra con aplicaciones #cloud es importante para poder crear #pipelines CI/CD.
En el caso de #Azure, se propone la creación de una integración con la solucion #AzureDevOps.
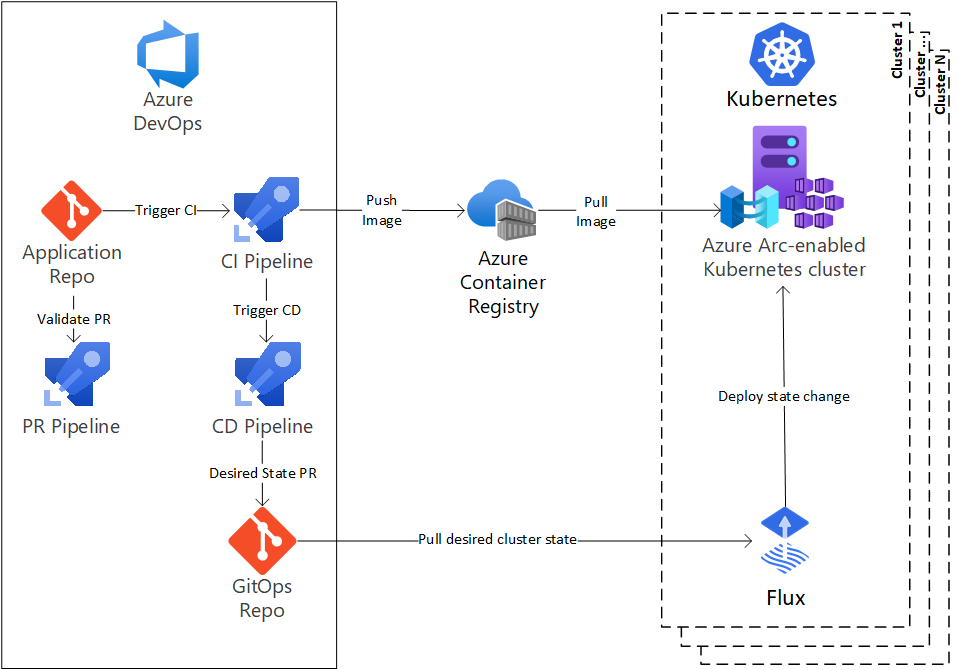
- El repositorio de aplicaciones contiene el código de la aplicación. Las plantillas de implementación de la aplicación residen en este repositorio en un formato genérico, como Helm o Kustomize. Cualquier cambio en este repo dispara el proceso de implementación.
- El registro de contenedor contiene todas las imágenes propias y de terceros que se usan en los entornos de Kubernetes.
- En este caso la integración esta realizada con #FluxCD, como servicio que se ejecuta en cada clúster y es responsable de mantener el estado deseado. Como mencionamos mas arriba, este servicio sondea el repositorio de GitOps en busca de cambios en su clúster y los aplica.
- Dentro de este esquema propuesto por Microsoft incorporan #AzureArc, una herramienta que ofrece una administración simplificada para Windows, Linux, SQL Server y para este caso particular, los clústeres de Kubernetes. En este caso, Azure Arc sirve para los diferentes entornos necesarios para la aplicación. Por ejemplo, un único clúster puede atender a un entorno de desarrollo y QA a través de espacios de nombres diferentes.
Beneficios y Conclusión
Git es el estándar de facto de los sistemas de control de versiones y es una herramienta de desarrollo de software común para la mayoría de los desarrolladores y equipos de software. Esto facilita que los desarrolladores familiarizados con Git se conviertan en colaboradores multifuncionales y participen en GitOps. Ademas un sistema de control de versiones le permite a un equipo rastrear todas las modificaciones a la configuración de un sistema.
GitOps aporta transparencia y claridad a las necesidades de infraestructura de una organización en torno a un repositorio central ue resuelven de forma muy simple las implementaciones y los rollbacks en infraestructuras complicadas.
| [popup_anything id=”2076″] |