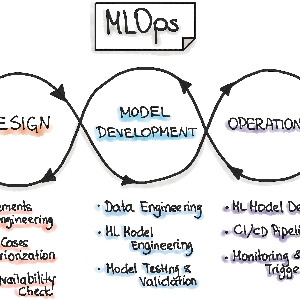
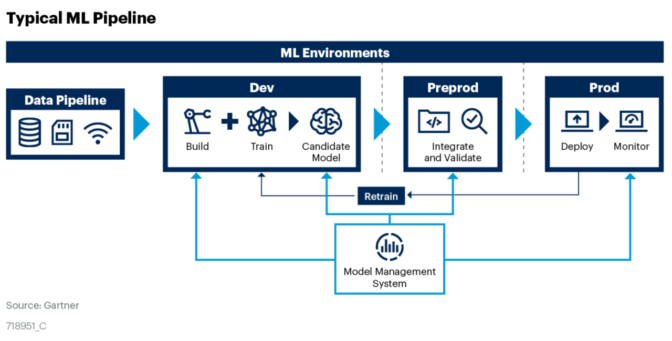
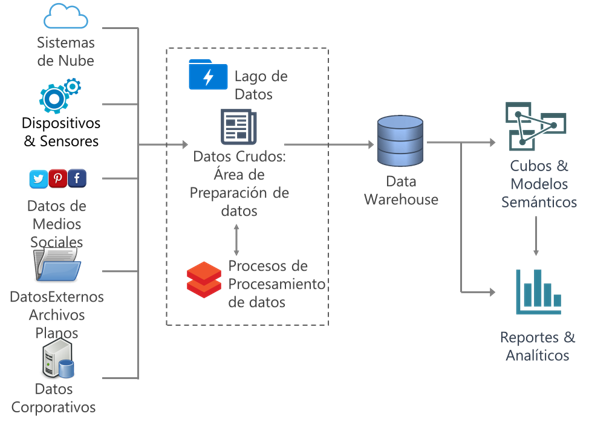
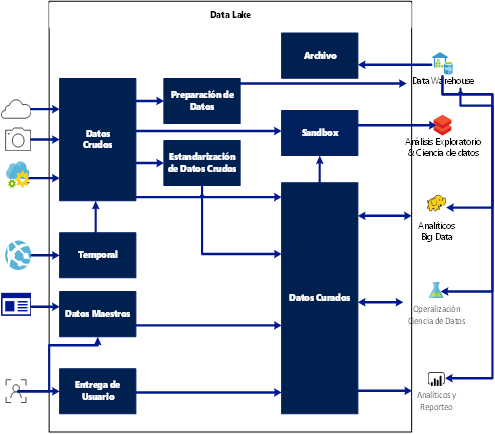
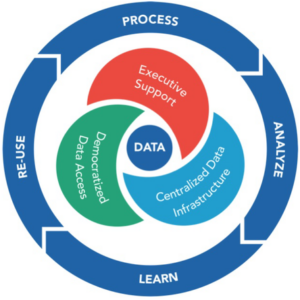
DataOps es un enfoque ágil que combina la ingeniería de datos en los procesos de operaciones. Su objetivo es crear valor comercial a partir de big data, promoviendo prácticas y procedimientos de gestión de datos que mejoren la velocidad y precisión de los análisis. Esto incluye automatización, acceso a datos, integración, control de calidad e implementación y gestión de modelos.
Los problemas resueltos por DataOps
Los principios fundamentales de #DataOps son simples. La disciplina está formada por la metodología ágil y se esfuerza por integrar análisis de datos continuos y en tiempo real en el proceso DevOps. En la práctica, significa incorporar DevOps y personal de gestión de datos en un equipo colaborativo.

Los equipos de DataOps valoran los análisis que funcionan y determinan el rendimiento del análisis de datos por los conocimientos que ofrecen. Aquí enumeramos algunos de los problemas que DataOps resuelve:
Corrección de errores: además de mejorar la agilidad de los procesos de desarrollo, DataOps tiene el poder de impulsar el proceso de gestión de incidentes. Es probable que la reparación de errores y defectos en los productos incluya aportes de expertos en datos y desarrollo, y también es una función comercial esencial. Con una mejor comunicación y colaboración entre grupos, el tiempo para responder a errores y defectos se reduce drásticamente.
Eficiencia: en DataOps, los equipos de datos y de desarrollo trabajan juntos y, por lo tanto, el flujo de información es horizontal. En lugar de comparar información en reuniones mensuales, el intercambio ocurre regularmente, lo que mejora significativamente la eficiencia de la organización.
Establecimiento de objetivos: DataOps proporciona a los equipos de desarrollo y administración, datos en tiempo real sobre el rendimiento de sus sistemas de datos. Dichos datos no son útiles para monitorear el éxito en relación con cualquier objetivo comercial. Sin embargo, si los procesos de negocios son los adecuados, los datos permiten a los gerentes ajustar y actualizar los objetivos de desempeño en tiempo real.
Colaboración limitada: implementar flujos de trabajo de DataOps significa aumentar la colaboración entre los equipos centrados en los datos y los equipos centrados en el desarrollo. DataOps también tiene como objetivo eliminar las diferencias entre estas dos funciones comerciales.
Respuesta lenta: uno de los desafíos más destacados que enfrentan las organizaciones hoy en día es responder a las solicitudes de desarrollo, tanto de los usuarios como de la alta dirección. En general, las solicitudes para integrar nuevas funciones incluyen los mismos reclamos que se envían hacia adelante y hacia atrás entre los científicos de datos y el equipo de desarrollo.
Como el equipo de DataOps involucra ambas funciones, el personal puede trabajar en conjunto en nuevas solicitudes. Permite que el equipo de desarrollo sea testigo del efecto que tienen las funciones originales en el flujo de datos a través de la organización. Además, ayuda a los equipos de datos a concentrarse mejor en procesar los objetivos reales de la organización.
Desafíos que enfrenta DataOps
Es un hecho que más datos significan más dependencias, más puntos de falla y administración. Entonces, ¿cuáles son los desafíos que enfrentan los equipos de DataOps?
Silos de datos: DataOps necesita hacer frente a los silos de datos que se crean como diferentes departamentos, y los equipos crean grupos de datos con procesos individualizados y estrechamente optimizados. Muchos grupos ven sus operaciones como inviolables en las que cada silo es una barrera hacia el éxito para implementar mejores estrategias de gestión de datos en toda la organización.
Falta de uso de la nube: la mayoría de los expertos en tecnología han entendido los beneficios que ofrece la nube. Sin embargo, aún así, muchas organizaciones no almacenan sus aplicaciones en la nube. Como resultado, los equipos de DataOps están sobrecargados con aplicaciones de datos que requieren más servidores de almacenamiento y grupos reconfigurados para garantizar la optimización de la base de datos.
Falta de habilidades: es un hecho que los profesionales de datos de todo tipo son escasos en el mercado tecnológico. La falta de disponibilidad de las personas adecuadas para administrar proyectos de Big Data significa que los proyectos no se ejecutan rápidamente o es probable que fracasen. Por lo tanto, poner más datos en un equipo que no tiene el conocimiento y los recursos para manejarlos es una forma de fallar.
¿Qué es un marco de DataOps?
El marco DataOps consta de cinco elementos esenciales y distintos. Los elementos son:
1.Tecnologías habilitadoras
Estas tecnologías incluyen inteligencia artificial (IA), aprendizaje automático (ML), herramientas de gestión de datos y automatización de TI.
2. Arquitectura adaptativa
La arquitectura adaptativa admite innovaciones continuas en los principales procesos, servicios y tecnologías.
3. Enriquecimiento de datos
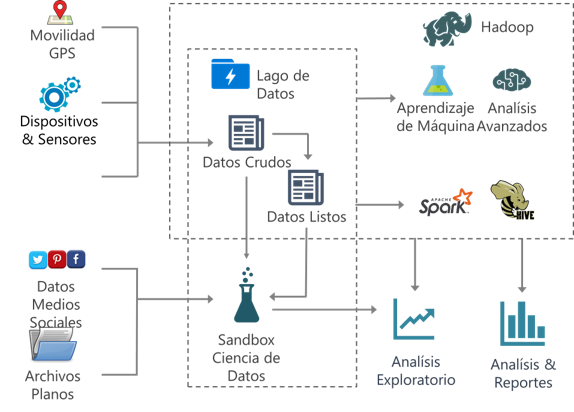
Estos datos son metadatos inteligentes creados por el sistema y colocados en un contexto útil para un análisis oportuno y preciso.
4. Metodología DataOps
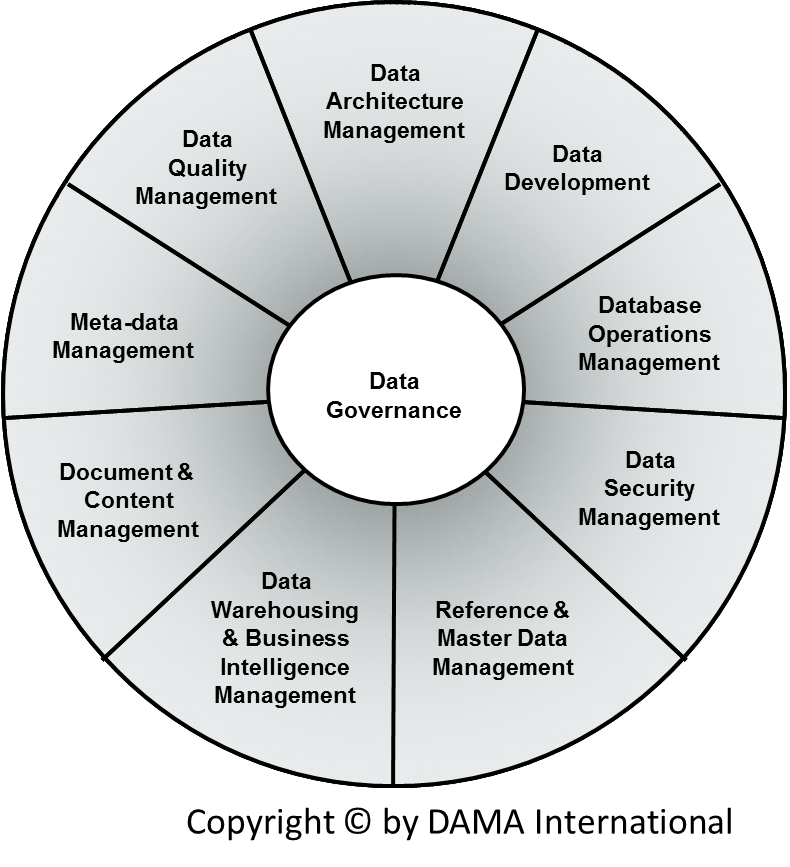
Esta metodología implica construir e implementar análisis de datos, siguiendo la gestión de su modelo y el gobierno de datos.
5.Gente y Cultura
Debe crear una cultura colaborativa entre las diferentes áreas de tecnología y el negocio. Esta cultura ayuda a poner la información correcta en el lugar correcto en el momento correcto para maximizar el valor de su organización.