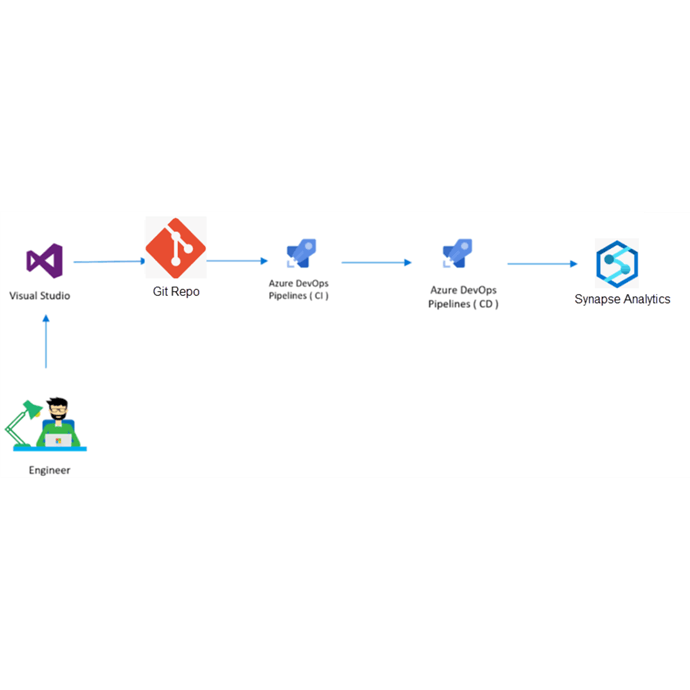
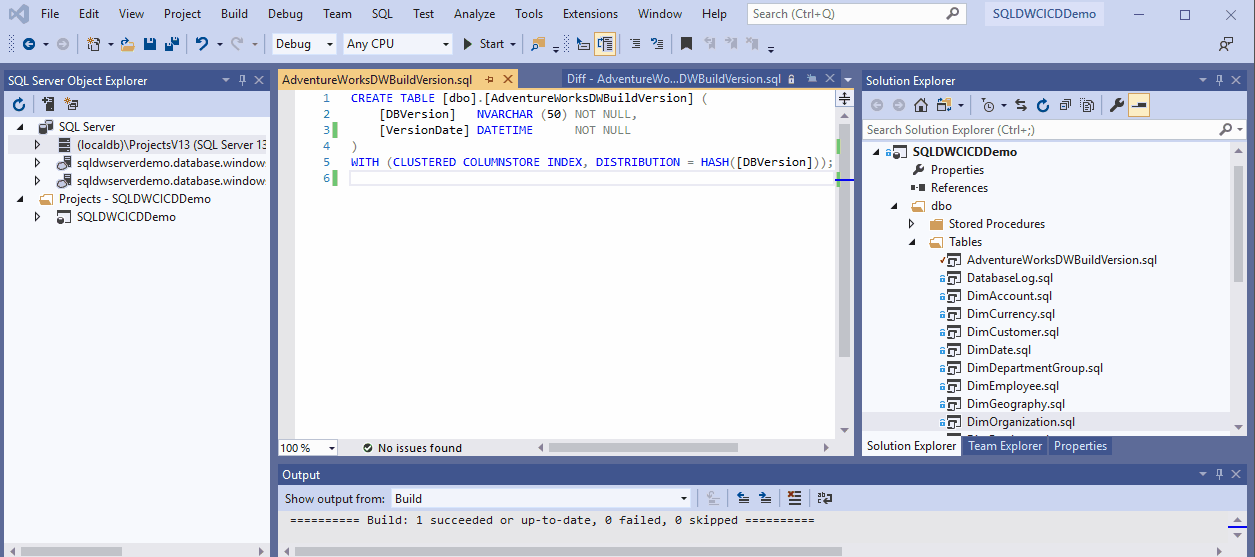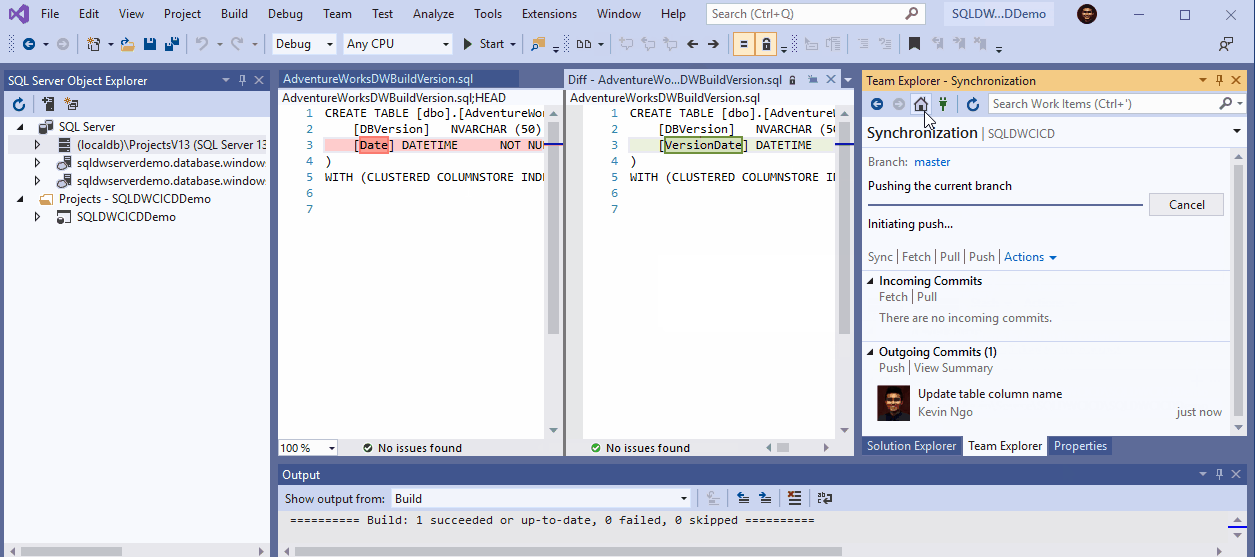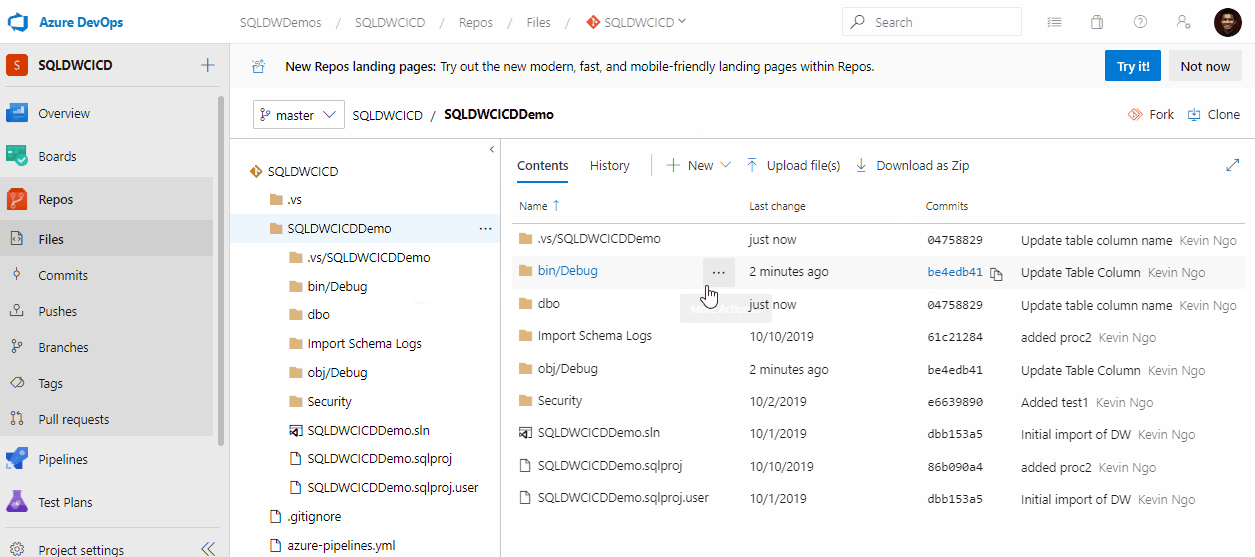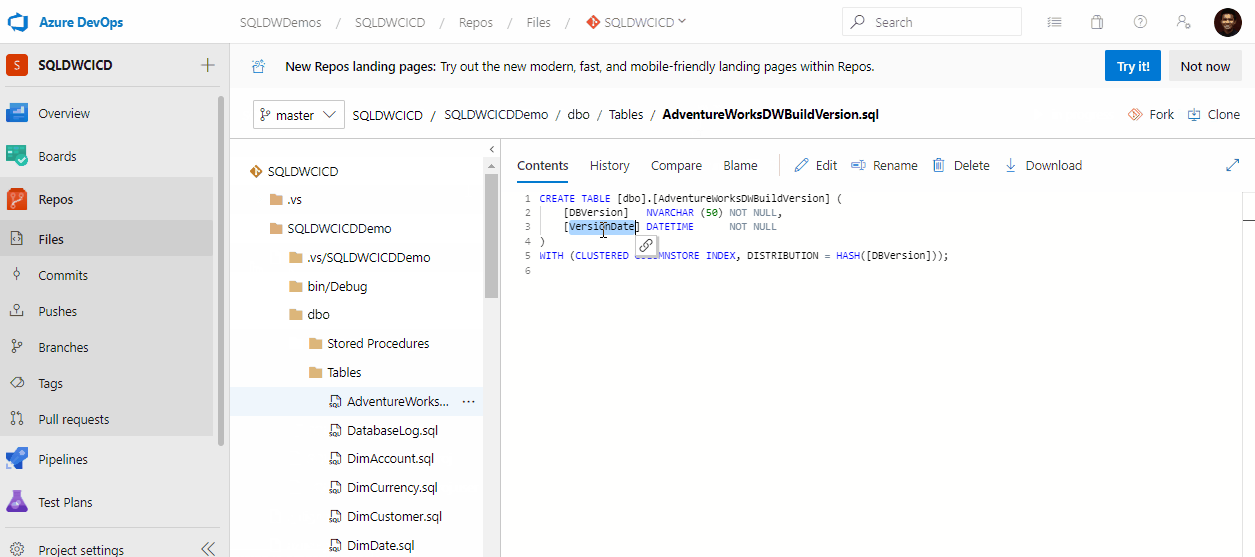
Las organizaciones de hoy en día están bajo una enorme presión por parte de la gerencia y los clientes para ofrecer productos y servicios de mayor calidad a costos más bajos, y a su vez, hacerlo utilizando los recursos existentes.
Se espera que cualquier gasto que hagan las empresas para ayudarlas a lograr este objetivo genere un #ROI medible y efectivo, y lo haga rápidamente. Aunque un número cada vez mayor de empresas aprovechan el IoT como parte de su estrategia de sustentabilidad, sigue existiendo una clara necesidad de poder demostrar los beneficios de hacerlo.
Los líderes del mercado de hoy entienden que el ROI es multidimensional y que, en muchos casos, el componente de ahorro de costos puede ser secundario a otros beneficios, como mejorar la satisfacción del cliente, el valor generado hacia la sustentabilidad, la diferenciación de la marca y la recopilación de datos precisos, todo lo cual también puede generar mayores ingresos.
A medida que las empresas hacen todo lo posible para retener y expandir las relaciones con los clientes existentes, sus activos más valiosos, los nuevos modelos comerciales y los servicios de valor agregado pasan a primer plano, y con ellos surgen nuevas oportunidades significativas para la empresa.
ROI de IoT: beneficios y más allá
Algunos beneficios relacionados al uso de #dispositivos #IoT es que se pueden convertir en métricas y esa recopilación de datos es instantánea y continua en el tiempo, proporcionando una forma de medir y cuantificar resultados.
Por ejemplo, el uso de energía. Los #sensores y análisis de IoT proporcionan un marco para monitorear, medir y catalogar datos de sensores ambientales y de energía, incluidos el consumo y la demanda de energía, la calidad del aire y el consumo de agua de manera granular y dinámica.
Tener todos esos datos de los dispositivos IoT al alcance de la mano produce información sobre las instalaciones y operaciones que conducen a decisiones más inteligentes. La “datificación” es el proceso de traducir operaciones que alguna vez fueron aparentemente invisibles en datos, y luego transformarlos en información para crear valor.
Encontrar el valor
Cada producto requiere cierto nivel de servicio y soporte y para ello las organizaciones adoptan cada vez más soluciones de servicio que identifican, diagnostican y resuelven problemas de forma remota.
Una estrategia de IoT ayuda a brindar servicios proactivos que mejoran el tiempo de actividad y reducen la cantidad de visitas de campo o la duración de las llamadas de soporte. Al mismo tiempo, reduce drásticamente los costos del servicio, allanando el camino para el desarrollo de servicios de valor agregado basados en los datos que se devuelven desde los dispositivos.
Las organizaciones que fueron las primeras en poner sus dispositivos en línea ahora se están dando cuenta de que el verdadero “oro” en IoT es tomar esos datos e integrarlos con servicios de #CRM, #ERP, #DataWarehouse, que permiten optimizar procesos comerciales críticos, reduciendo llamadas de servicio, tiempos y gestión eficiente de retiro de productos, etc.
Los datos de IoT de los activos conectados, en colaboración con otros sistemas empresariales, pueden proporcionar visibilidad y automatización que antes no eran posibles en todas las organizaciones.
Por ejemplo, los datos de productos que fluyen a través de un sistema CRM también se pueden enviar a facturación o a un sistema de gestión de la cadena de suministro, lo que ayuda a eliminar los pasos manuales propensos a errores y brinda nuevas oportunidades de ventas para cosas como la reposición de consumibles o la renovación de la garantía. Además, la integración con el control de calidad o la gestión del ciclo de vida del producto (#PLM) puede ayudar a mejorar las características del producto en función de datos del mundo real que muestran patrones de uso o problemas del equipo, lo que ayuda a mejorar la satisfacción del cliente y agilizar los procesos.
Hoy los dispositivos IoT ofrecen a las empresas la capacidad de brindar un mejor servicio a un menor costo, minimizar el tiempo de respuesta y maximizar el uso y el alcance de sus recursos. Al mismo tiempo, permite mejorar los ingresos, los márgenes, la participación de mercado y, lo que es más importante, la satisfacción del cliente. Las soluciones de IoT pueden ser la clave para brindar un servicio de excelencia a sus clientes, obtener información comercial certera, mejorar los procesos comerciales y generar valor en productos, servicios e innovación.
Medición de su desarrollo sostenible
IoT puede proporcionar una mayor visibilidad de sus procesos y condiciones ambientales, específicamente el consumo de energía, la calidad del aire y la calidad del agua. Examinar esos datos a lo largo del tiempo le brindará un mecanismo de retroalimentación que le permitirá “ver” el impacto de sus esfuerzos.
Dependiendo de su empresa y sus objetivos/prioridades, una o más métricas pueden ser más “ponderadas” para usted que para otra organización. En última instancia, su desempeño en estas categorías debe combinarse en un mecanismo de informes integral, una especie de “Cuadro de Mando Integral de Sustentabilidad”, que se puede evaluar fácilmente. No sólo obtendrá una mejor perspectiva de la eficacia de lo que está haciendo, sino que sus accionistas, inversores y clientes tendrán una forma cuantificable de evaluar su desempeño de sustentabilidad a lo largo del tiempo.
Estas medidas también se pueden comparar con otros datos, como los cambios en el compromiso de los empleados, la satisfacción del cliente o los datos de ventas. Las correlaciones pueden indicar que sus esfuerzos están teniendo un impacto y que su capacidad para cuantificar los esfuerzos de sustentabilidad está, por ejemplo, aumentando el valor de su marca o mejorando el compromiso de los empleados.
[popup_anything id=”2076″]