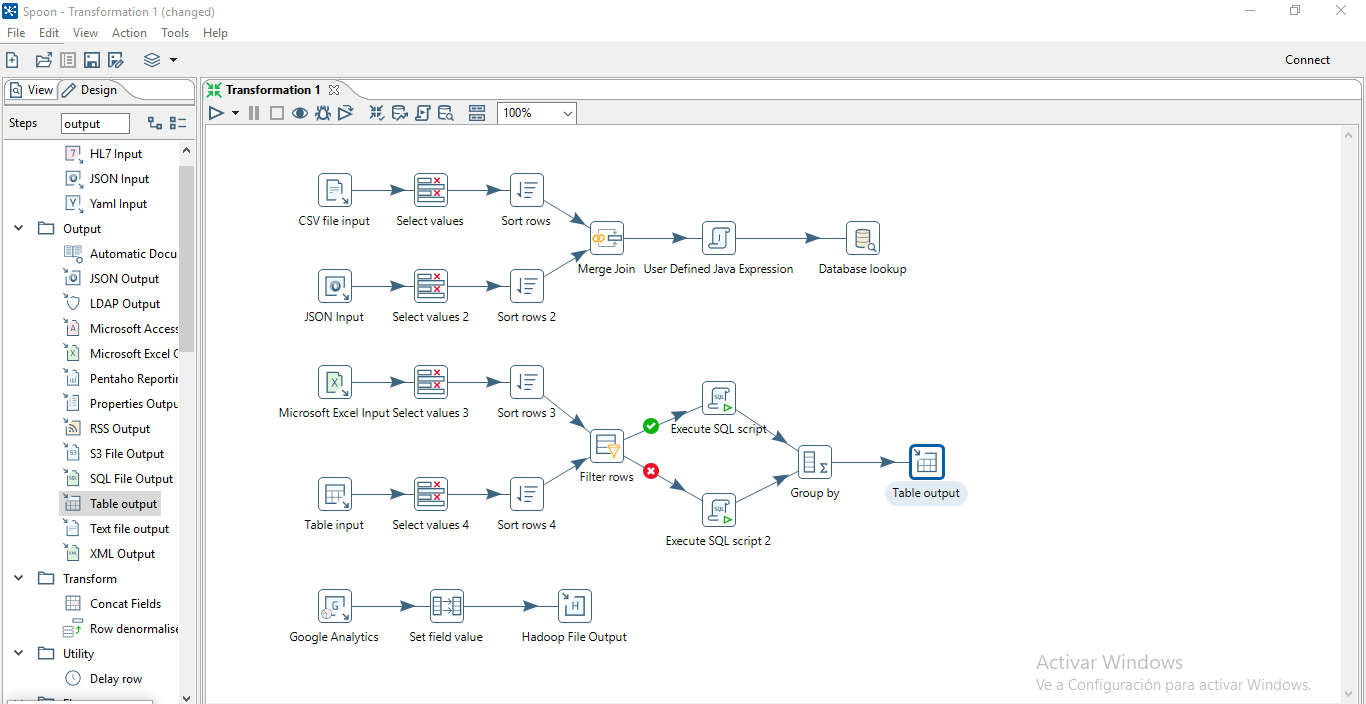
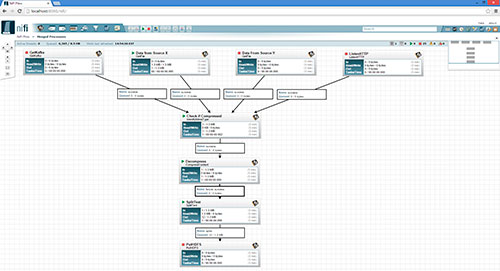
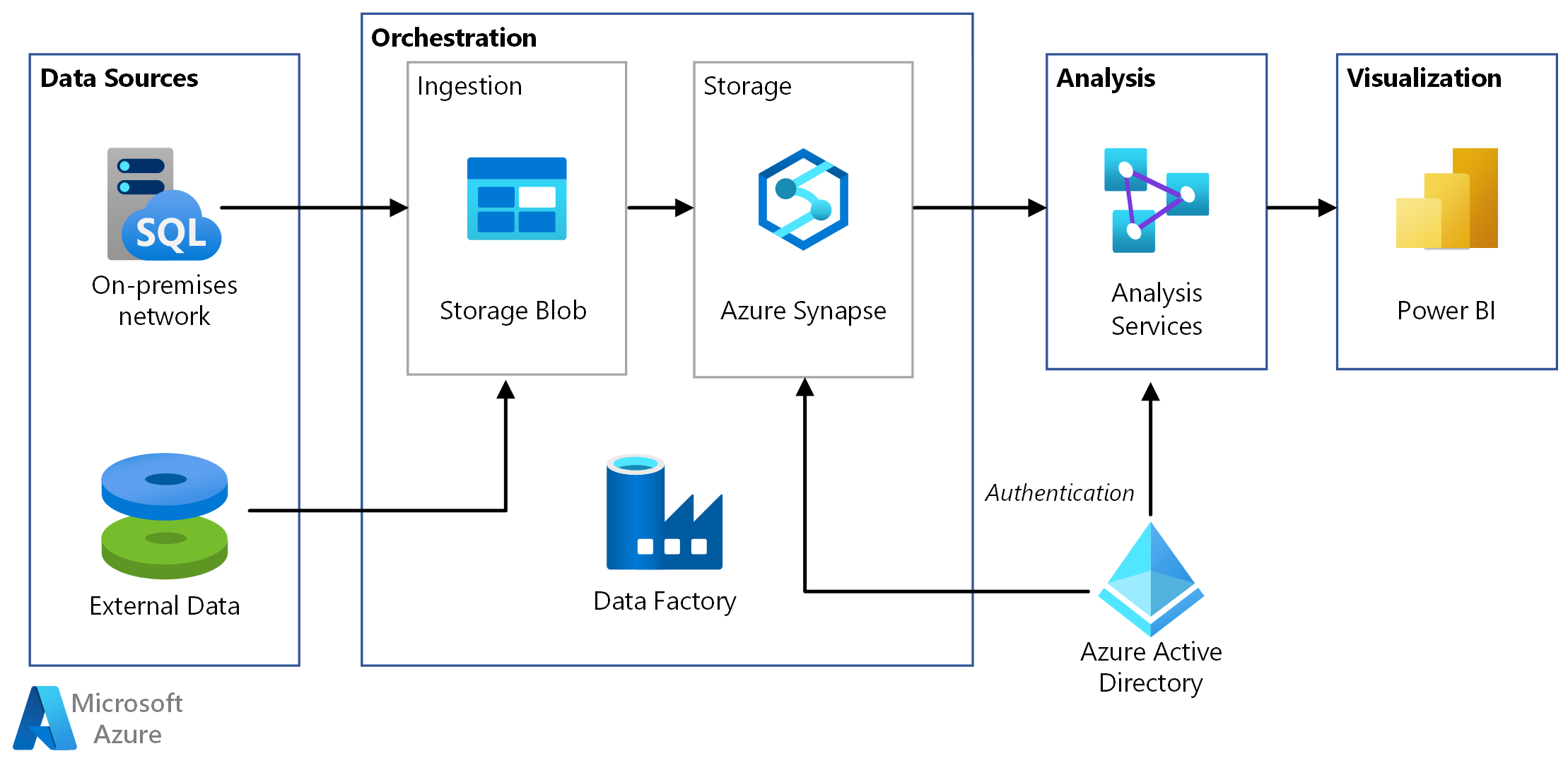
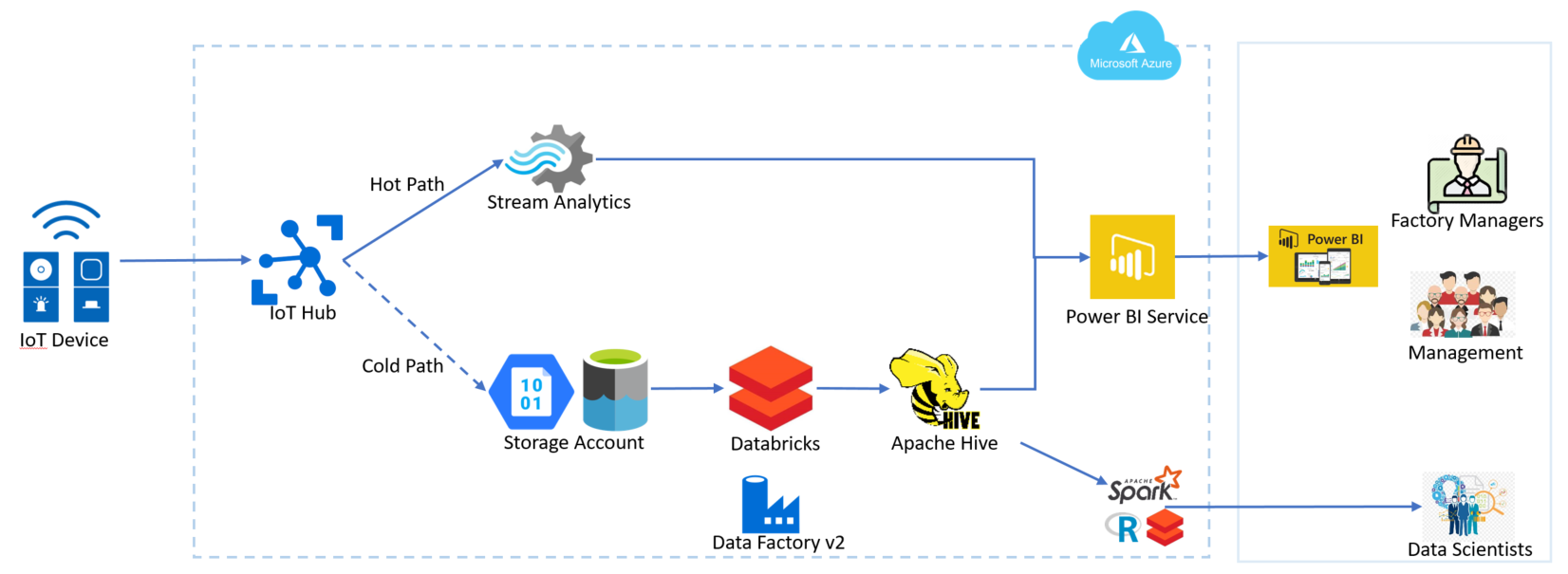
Tremendo título marketinero, ¿no?
Por lo general, cuando los gurús pronostican este tipo de cambios tan drásticos suelen equivocarse feo, quedó demostrado durante la pandemia y el término “nueva realidad”.
Los cambios pueden ser graduales, pero rara vez un cambio viene dado por la desaparición completa de algo.
La realidad, es que el #ETL viene presentando varios cambios. Quizás el más significativo es el concepto de #ELT que viene empujado por las arquitecturas de #DataLake.
Escribimos varias notas de ETL y ELT. Pero ahora vamos a hablar del “ETLess” o Zero ETL.
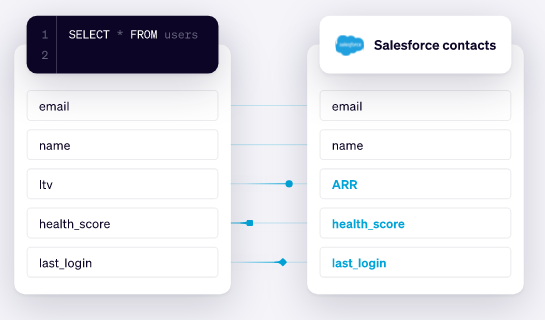
#ZeroETL es un enfoque que busca reducir o eliminar la necesidad de realizar una extracción, transformación y carga (ETL) de datos en un proceso de análisis de datos. O al menos la necesidad de hacerlo de forma manual.
Por ejemplo, #Databricks y #Snowflake vienen trabajando en simplificar los procesos de Extracción, Transformación y Carga. Tanto Snowflake como Databricks tienen soluciones que se enfocan en reducir la complejidad y la necesidad de ETL tradicional.
Snowflake tiene una arquitectura de nube nativa que permite cargar y consultar datos en tiempo real, lo que reduce la necesidad de procesos de transformación y limpieza de datos complejos. También tiene funciones de preparación de datos incorporadas que permiten transformaciones en el momento de la consulta, lo que a menudo elimina la necesidad de ETL previo.
Por otro lado, Databricks cuenta con herramientas como Delta Lake y la funcionalidad de transformación de datos en tiempo real de Spark Streaming, lo que permite trabajar con datos en su estado natural, sin tener que extraerlos, transformarlos y cargarlos en un almacén de datos.
AWS es otro de los grandes impulsores del concepto de Zero ETL. El avance de la #IA hace que muchos expertos pongan las actividades manuales en la mira de la automatización. Pero la realidad es que estamos lejos de tal simplificación.
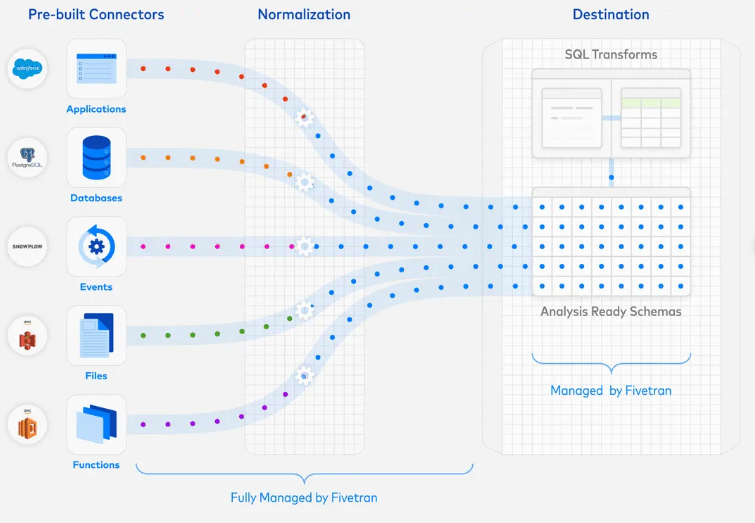
Lo cierto es que los pipelines de datos están confluyendo hacia una mejorar canalización y transporte de la información, haciendo que las necesidades de ETL disminuyan. La práctica de la extracción, que solía ser muy costosa, se está simplificando por medio de conectores prefabricados que permiten integrar miles de plataformas con muy poca configuración de por medio. La transformación es la que sigue siendo un verdadero problema. La transformación implica la limpieza, validación, normalización, agregación y enriquecimiento de los datos para asegurarse de que sean precisos, coherentes y relevantes para su uso previsto. Pero aún la calidad de los datos sigue siendo un verdadero dolor de cabeza.
Desde tiempo atrás a hoy, se han desarrollado técnicas y creado herramientas más avanzadas para mejorar la calidad de los datos. La aparición de herramientas de integración de datos permitió la automatización de muchas tareas de limpieza y transformación de datos, lo que redujo el riesgo de errores humanos y mejoró la eficiencia.
Además, se han creado estándares de calidad de datos y se han establecido mejores prácticas para asegurar la integridad y la precisión de los datos.
Las necesidades de mayor información y el camino de las organizaciones hacia el #DataDriven, hace que la implementación de procesos de calidad de datos sea una tarea crítica para muchas organizaciones que dependen de los datos para tomar decisiones importantes.
Lo bueno es que la inteligencia artificial y el aprendizaje automático están permitiendo nuevas técnicas para mejorar la calidad de los datos, como la identificación de patrones de datos inconsistentes o la corrección automática de errores comunes; pero nace un nuevo problema de calidad relacionado con los sesgos cognitivos.
Los sesgos de datos son errores sistemáticos en la recopilación, el análisis o la interpretación de los datos que pueden generar conclusiones inexactas o incompletas. Los sesgos de datos pueden ser el resultado de diferentes factores, como la falta de representatividad de la muestra, la mala calidad de los datos, la falta de diversidad en los datos, la selección sesgada de las variables o la falta de contexto.
Los sesgos de datos pueden tener consecuencias negativas, como la toma de decisiones incorrectas o injustas, la discriminación y la creación de estereotipos. Para evitar los sesgos de datos, es importante tener en cuenta la calidad de los datos, la diversidad de la muestra, la objetividad en la selección de las variables, la transparencia en la metodología y el contexto en el que se recopilaron los datos.
Los sesgos en la data pueden ser un problema serio en cualquier etapa del proceso ETL, ya que pueden llevar a conclusiones incorrectas o discriminación en la toma de decisiones. Para abordar los sesgos de la data, es importante comprender las fuentes de sesgo, incluyendo la selección de datos, la recopilación de datos, el preprocesamiento y la interpretación de los resultados.
Es importante tener en cuenta la necesidad de tener datos no sesgados en todo el proceso ETL para garantizar que los resultados sean precisos y justos. Esto puede implicar la selección cuidadosa de datos de fuentes diversas, la revisión rigurosa de los datos para identificar y abordar cualquier sesgo, y la aplicación de técnicas estadísticas para garantizar la calidad y la integridad de los datos. Además, es esencial que se realice una revisión constante y periódica de la calidad de datos para asegurarse de que los datos sigan siendo precisos y no sesgados a lo largo del tiempo.
De manera que… ¿El ETL va camino a desaparecer?
De nuestra parte creemos que no, ni los procesos ETL, ni los ELT, ni ETL inverso, ni nada. Ni cerca están de desaparecer. Nacerán nuevas y mejores técnicas, pero hay que seguir invirtiendo, esforzándonos y mejorando todos los procesos de Extracción, Transformación y Carga; porque para ser Data Driven se necesitan datos limpios.
Van 5 consejos para mejorar tus procesos ETL:
- Antes de comenzar cualquier proceso ETL, es importante analizar la fuente de datos y su calidad para determinar si se necesita limpieza o transformación previa. Si la fuente de datos es limpia y consistente, el proceso de ETL será más rápido y eficiente.
- Al limitar la cantidad de datos que se procesan durante el proceso ETL, se puede mejorar significativamente el tiempo de ejecución. Esto se puede lograr a través de filtros, consultas selectivas y otras técnicas que permiten seleccionar solo los datos necesarios para el análisis.
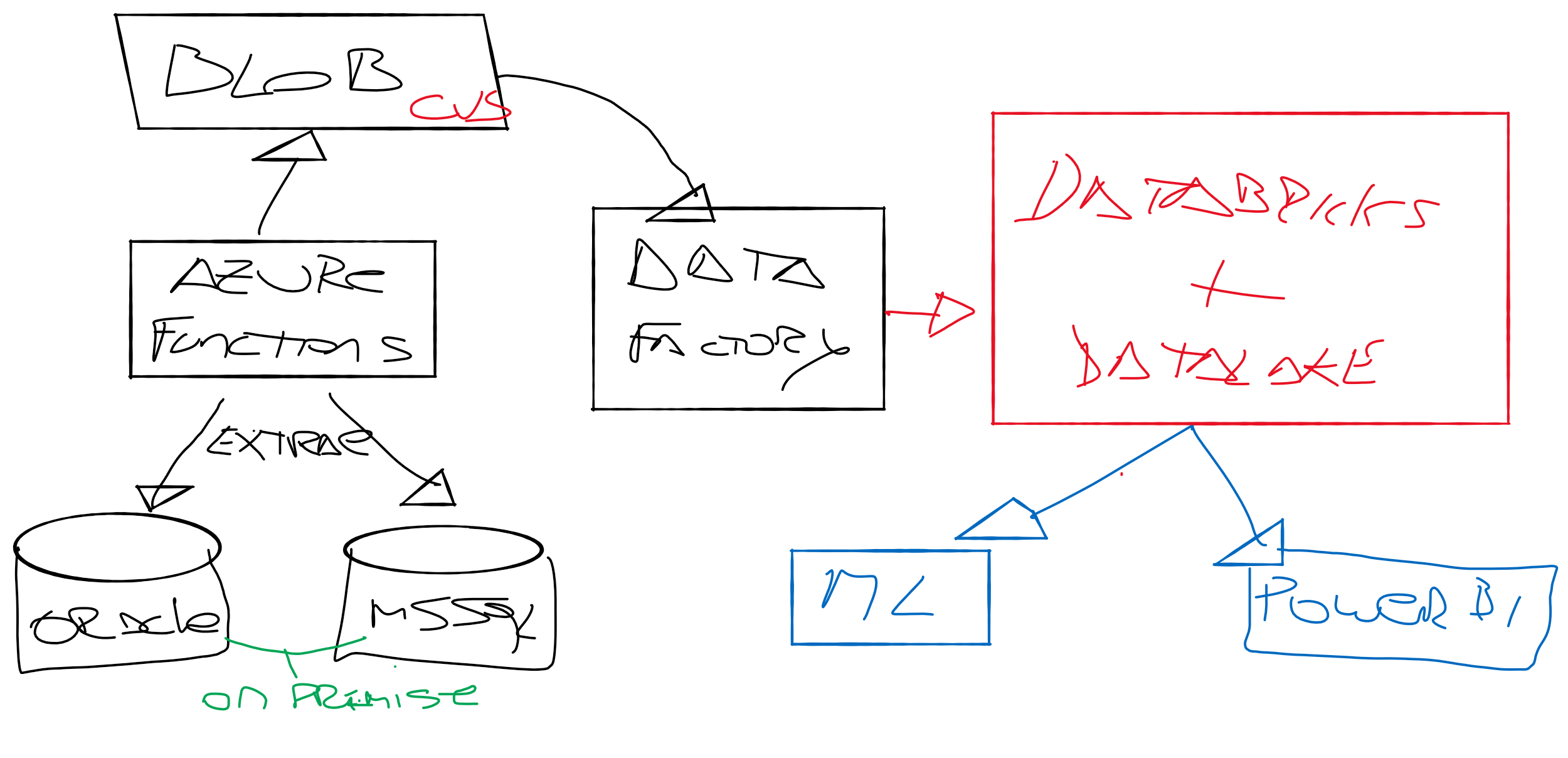
- El uso de herramientas y tecnologías modernas puede mejorar significativamente la eficiencia de un proceso ETL. Por ejemplo, el uso de plataformas en la nube como AWS o Azure, o herramientas de automatización como Airflow, puede reducir el tiempo y los recursos necesarios para realizar un proceso ETL.
- La automatización del proceso ETL puede reducir significativamente el tiempo y los recursos necesarios para completar un proceso de carga. La automatización también puede reducir la posibilidad de errores humanos y mejorar la calidad de los datos.
- Es importante monitorear y ajustar el proceso ETL continuamente para mejorar su eficiencia. Esto puede incluir el ajuste de parámetros de configuración, la optimización de consultas y la adición de nuevos filtros para reducir la cantidad de datos procesados.

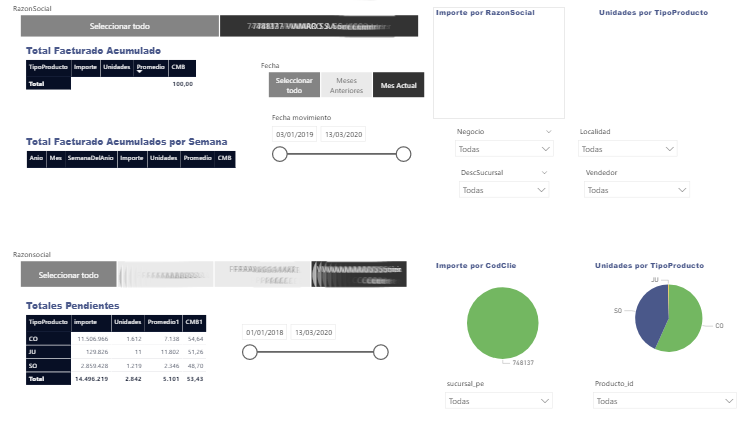
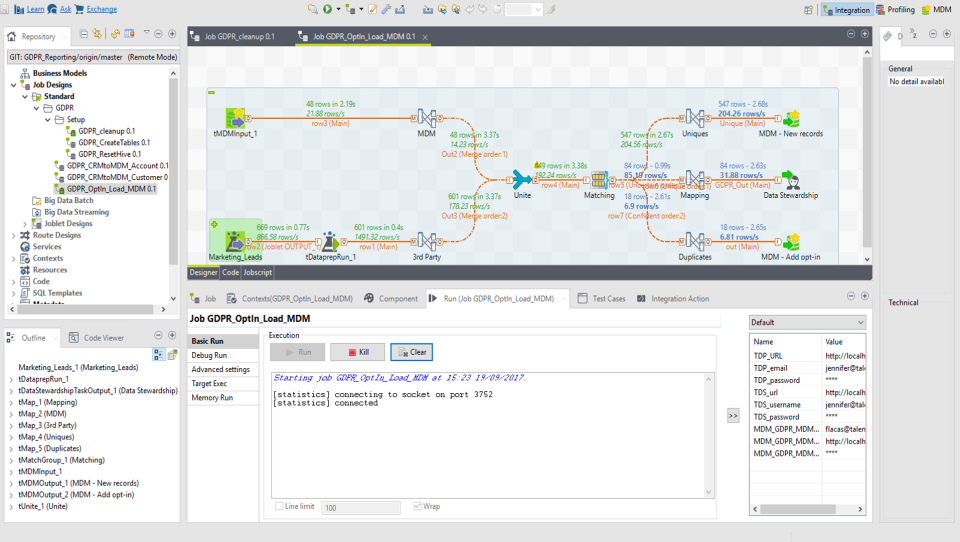 de datos, aplicaciones empresariales y servicios web. Estos componentes se pueden personalizar y combinar para adaptarse a las necesidades específicas de cada proyecto.
de datos, aplicaciones empresariales y servicios web. Estos componentes se pueden personalizar y combinar para adaptarse a las necesidades específicas de cada proyecto.