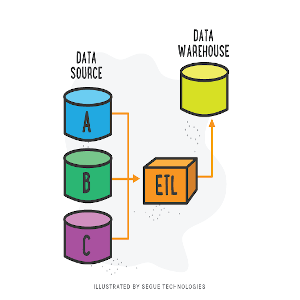
ETL es un acrónimo que significa Extracción, Transformación y Carga. Es un proceso utilizado en la gestión de datos para recopilar datos de diferentes fuentes, limpiarlo y transformarlo en un formato adecuado para su análisis y utilización en un sistema de información. Luego se carga en una base de datos o sistema de almacenamiento para su uso futuro. Es una técnica comúnmente utilizada en la integración de datos.

¿Que herramienta de #ETL usar?
Talend es una plataforma de integración de datos que permite la conexión, la transformación y la integración de datos entre diferentes sistemas. Utiliza una interfaz gráfica de usuario para diseñar flujos de trabajo de integración de datos, lo que facilita la creación de tareas de integración de datos para usuarios sin experiencia en programación. Además, #Talend ofrece una amplia gama de componentes preconstruidos que se pueden utilizar para conectarse a diferentes fuentes de datos, como bases 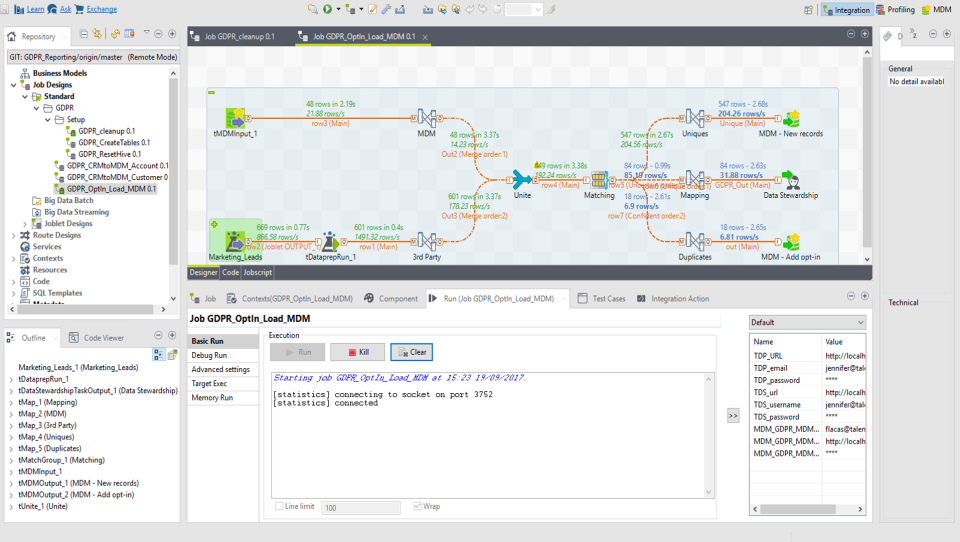 de datos, aplicaciones empresariales y servicios web. Estos componentes se pueden personalizar y combinar para adaptarse a las necesidades específicas de cada proyecto.
de datos, aplicaciones empresariales y servicios web. Estos componentes se pueden personalizar y combinar para adaptarse a las necesidades específicas de cada proyecto.
______________
Pentaho Data Integration (PDI) es una herramienta de integración de datos open-source que permite la conexión, la transformación y la integración de datos entre diferentes sistemas. Utiliza una interfaz gráfica de usuario para diseñar flujos de trabajo de integración de datos, conocida como Spoon, que facilita la creación de tareas de integración de datos para usuarios sin experiencia en programación.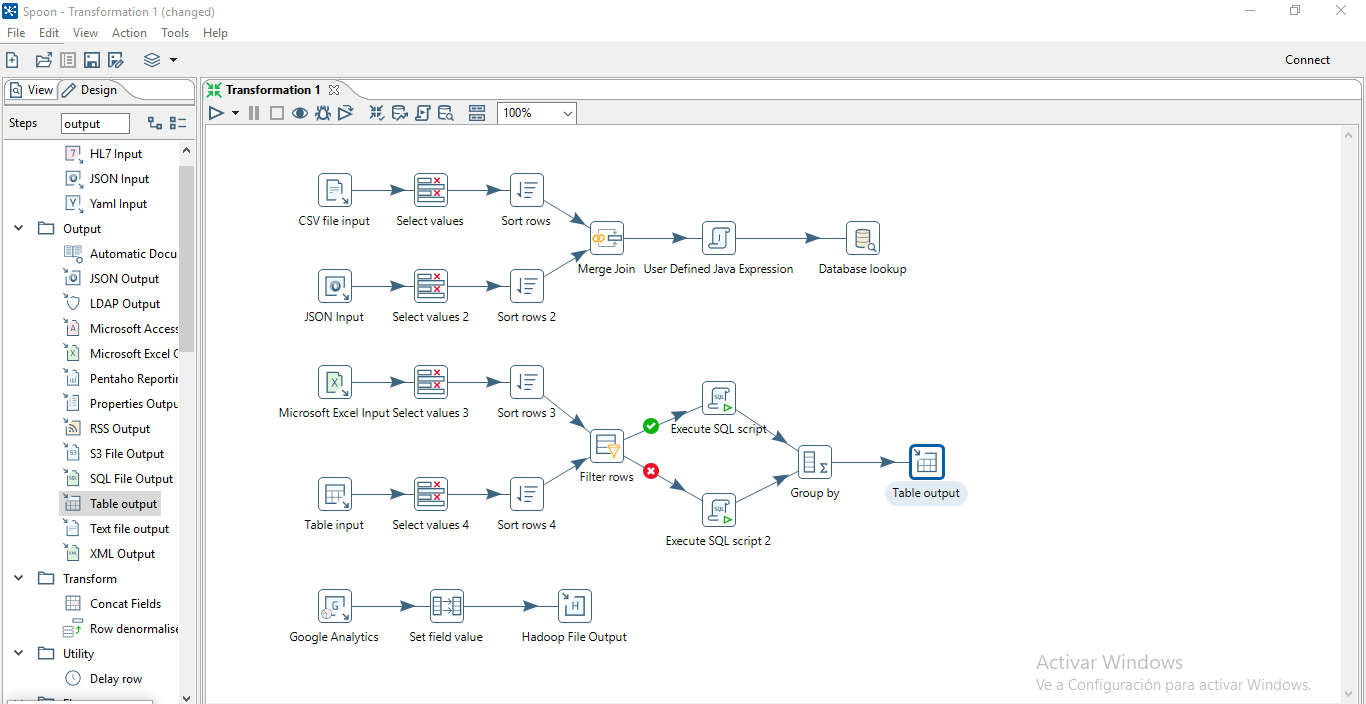
PDI tiene una amplia gama de componentes preconstruidos, llamados transformaciones y tareas, que se pueden utilizar para conectarse a diferentes fuentes de datos, como bases de datos, aplicaciones empresariales y servicios web. Estos componentes se pueden personalizar y combinar para adaptarse a las necesidades específicas de cada proyecto. También cuenta con herramientas para la limpieza y análisis de datos, así como para la generación de informes y la creación de dashboards.
PDI se utiliza en conjunto con el resto de herramientas de la suite Pentaho, como #Pentaho Report Designer y Pentaho Analyzer, para crear soluciones completas de Business Intelligence.
______________
Apache NiFi es una plataforma de flujo de datos open-source que permite la captura, flujo, transformación y distribución de datos a través de una interfaz gráfica de usuario fácil de usar. Es una herramienta altamente escalable y escalable que se puede utilizar para automatizar y optimizar los flujos de trabajo de datos en una variedad de entornos, desde pequeñas aplicaciones hasta implementaciones de gran escala.
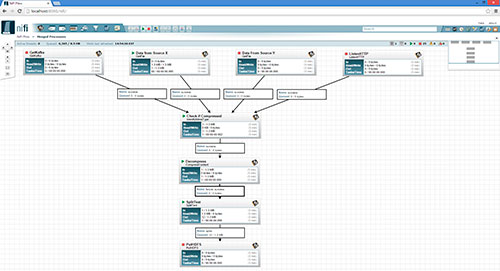
NiFi utiliza una arquitectura basada en flujos para organizar y controlar los datos, lo que permite a los usuarios crear flujos de trabajo de integración de datos mediante la arrastrado y soltado de componentes preconstruidos en una interfaz gráfica de usuario. Estos componentes, conocidos como procesadores, se pueden utilizar para realizar tareas como la captura de datos, la transformación de datos, la validación de datos y la distribución de datos a diferentes destinos.
#NiFi también cuenta con características avanzadas, como la capacidad de manejar y procesar datos en tiempo real, la seguridad y el control de acceso, y la monitorización y la gestión de flujos de trabajo. También tiene una integración con otras herramientas y tecnologías de big data, como Apache #Kafka, Apache #Storm y Apache #Hadoop.
Y que hay de los serverless, los que son ejecutados en las #cloud?
Azure Data Factory (ADF) es una plataforma de integración de datos en la nube de Microsoft que permite la conexión, la transformación y la integración de datos entre diferentes sistemas. Es un servicio en la nube que se ejecuta en Microsoft Azure y se utiliza para automatizar los flujos de trabajo de integración de datos.
ADF utiliza una interfaz gráfica de usuario para diseñar flujos de trabajo de integración de datos, llamados “pipelines”, que se componen de diferentes “actividades” que representan tareas específicas, como la copia de datos, la transformación y el procesamiento. Estas actividades se pueden utilizar para conectarse a diferentes fuentes de datos, como bases de datos, aplicaciones empresariales y servicios web, y para copiar y mover datos entre estos sistemas.
ADF también cuenta con herramientas para la automatización de tareas, como la planificación de trabajos y la generación de informes, y cuenta con integración con otras herramientas y tecnologías de Microsoft Azure, como #Azure Data Lake Storage, Azure SQL Data Warehouse y #PowerBI.
Ademas, ADF tiene la capacidad de escalar automáticamente para manejar grandes volúmenes de datos y también cuenta con una variedad de opciones de seguridad y cumplimiento.
______________
AWS Glue es una plataforma de integración de datos en la nube de Amazon Web Services (AWS) que permite la conexión, la transformación y la integración de datos entre diferentes sistemas. Es un servicio en la nube que se ejecuta en AWS y se utiliza para automatizar los flujos de trabajo de integración de datos.
AWS #Glue ofrece una interfaz gráfica de usuario para diseñar flujos de trabajo de integración de datos, llamados “jobs”, que se componen de diferentes “tareas” que representan tareas específicas, como la copia de datos, la transformación y el procesamiento. Estas tareas se pueden utilizar para conectarse a diferentes fuentes de datos, como bases de datos, aplicaciones empresariales y servicios web, y para copiar y mover datos entre estos sistemas.
AWS Glue también cuenta con herramientas para la automatización de tareas, como la planificación de trabajos y la generación de informes, y cuenta con integración con otras herramientas y tecnologías de AWS, como Amazon S3, Amazon Redshift y Amazon Athena.
Ademas, AWS Glue cuenta con un catálogo de metadatos, que permite a los usuarios registrar y gestionar información sobre sus datos, como estructura, relaciones y calidad de los datos. También tiene la capacidad de escalar automáticamente para manejar grandes volúmenes de datos y cuenta con opciones de seguridad y cumplimiento. Asimismo, AWS tiene otro servicio que se llama #DataPipeline.
AWS Data Pipeline es un servicio de #Amazon Web Services (#AWS) que permite automatizar la transferencia y la transformación de datos entre diferentes sistemas de almacenamiento y procesamiento de datos. Es un servicio en la nube que se ejecuta en AWS y se utiliza para crear flujos de trabajo de integración de datos y automatizar tareas relacionadas con la gestión de datos.
Con AWS Data Pipeline, los usuarios pueden crear flujos de trabajo de integración de datos mediante la definición de “tareas” y “relaciones” entre ellas. Cada tarea representa una actividad específica, como la copia de datos desde una fuente a un destino, la ejecución de una transformación o la ejecución de un script. Las relaciones entre las tareas definen el orden en que deben ejecutarse las tareas.
AWS Data Pipeline también cuenta con herramientas para la planificación automatizada de tareas, como la programación de trabajos y la generación de informes, y cuenta con integración con otras herramientas y tecnologías de AWS, como Amazon #S3, Amazon #RDS y Amazon EMR.
Ademas, AWS Data Pipeline tiene la capacidad de escalar automáticamente para manejar grandes volúmenes de datos y cuenta con opciones de seguridad y cumplimiento. También permite a los usuarios monitorear y supervisar el progreso de los flujos de trabajo y detectar y solucionar problemas de manera eficiente.
______________
Google Cloud Dataflow es una plataforma de procesamiento de datos en la nube de #Google Cloud Platform (#GCP) que permite la ejecución de tareas de procesamiento y transformación de datos a gran escala. Es un servicio en la nube que se ejecuta en GCP y se utiliza para crear flujos de trabajo de integración de datos y automatizar tareas relacionadas con la gestión de datos.
Con Cloud #Dataflow, los usuarios pueden crear flujos de trabajo de procesamiento de datos mediante la definición de “tareas” y “relaciones” entre ellas. Cada tarea representa una actividad específica, como la lectura de datos desde una fuente, la ejecución de una transformación, la escritura de datos en un destino. Las relaciones entre las tareas definen el orden en que deben ejecutarse las tareas.
Dataflow permite a los usuarios crear flujos de trabajo utilizando un lenguaje de programación #Java o #Python, y utiliza un modelo de programación de tuberías y filtros para procesar los datos. Ademas, Dataflow es escalable y maneja de manera automática la distribución y el balanceo de carga para procesar grandes volúmenes de datos.
Dataflow también cuenta con herramientas para la planificación automatizada de tareas, como la programación de trabajos y la generación de informes, y cuenta con integración con otras herramientas y tecnologías de GCP, como #BigQuery, Cloud Storage, Cloud Pub/Sub.
Esperamos que esta nota haya sido de interés, y si tienes dudas puedes ponerte en contacto con nosotros.
[popup_anything id=”2076″]



