Introducción
Synapse es una plataforma de #LakeHouse de #Azure. Permite armar un #datawarehouse, un #datalake e incluso correr scripts con desarrollos de #ML.
#AzureDevOps es un producto de Microsoft que proporciona funciones de control de versiones, informes, gestión de requisitos, gestión de proyectos, compilaciones automatizadas, pruebas y gestión de versiones.
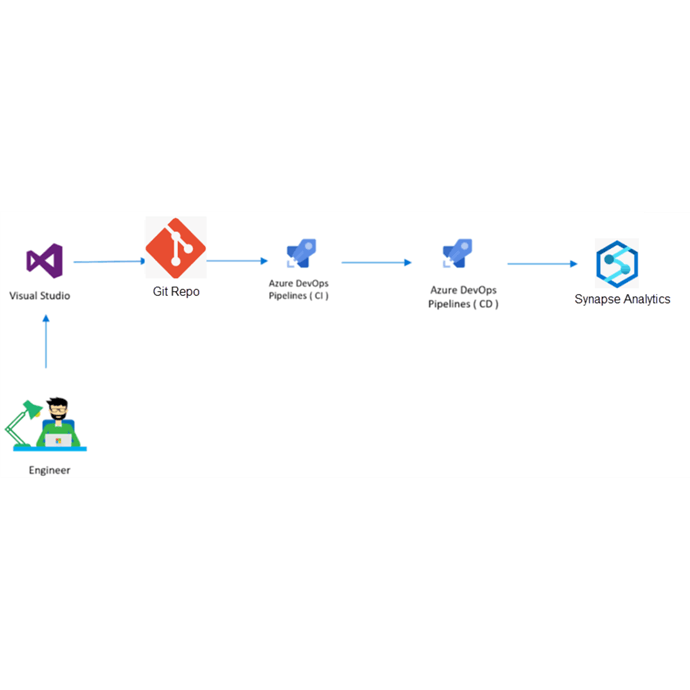
Para la administración de los desarrollos que corren en la plataforma de #Synapse, es de vital importancia entender el enfoque CI/CD para un pipeline de data.
El enfoque sobre cómo manejar CI/CD con Azure Synapse difiere bastante de su enfoque de “desarrollo de software”. La única rama que puede usar para implementar su código es la rama de publicación (workspace_publish). Esta rama se creará/actualizará cuando presione publicar en su interfaz de usuario de Synapse, después de realizar cualquier cambio.
La rama de trabajo real, donde se integran todas las solicitudes de extracción para implementar nuevas funciones, es la rama de colaboración (rama principal). Esta es también la base para sus publicaciones automatizadas.
El pipeline CI
La construcción ya está prácticamente hecha, porque todo ya está preparado como una solución lista para la implementación. Esta es la razón por la que solo necesita empaquetar su código con fines de trazabilidad y reutilización.
El pipeline CD
Esta tarea también es bastante fácil, porque puede usar una tarea predefinida llamada “Implementación del espacio de trabajo de Synapse”. Aquí solo necesita insertar su Workspace de destino, autenticarse a través de Service Connection (Suscripción). Además, debe desactivar los disparadores para una compilación limpia, pero también hay una tarea previa a la compilación para usar en Azure DevOps llamada “toggle-triggers-dev”.
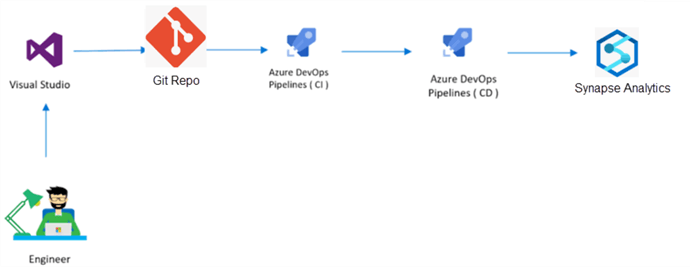
CI/CD
Y ahora ambos juntos en una canalización yaml completamente funcional. El activador siempre se activa cuando se publica una nueva plantilla de Synapse en nuestra rama de publicación.
