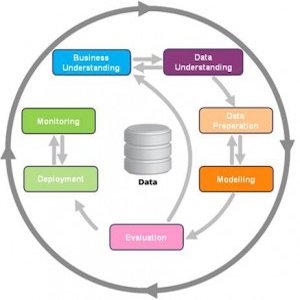
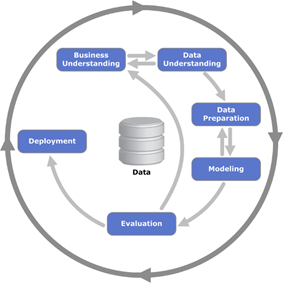
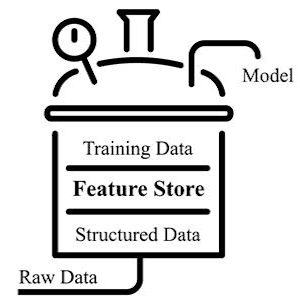
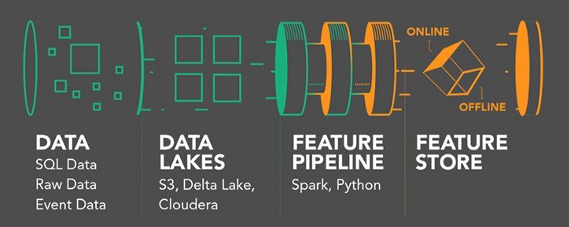
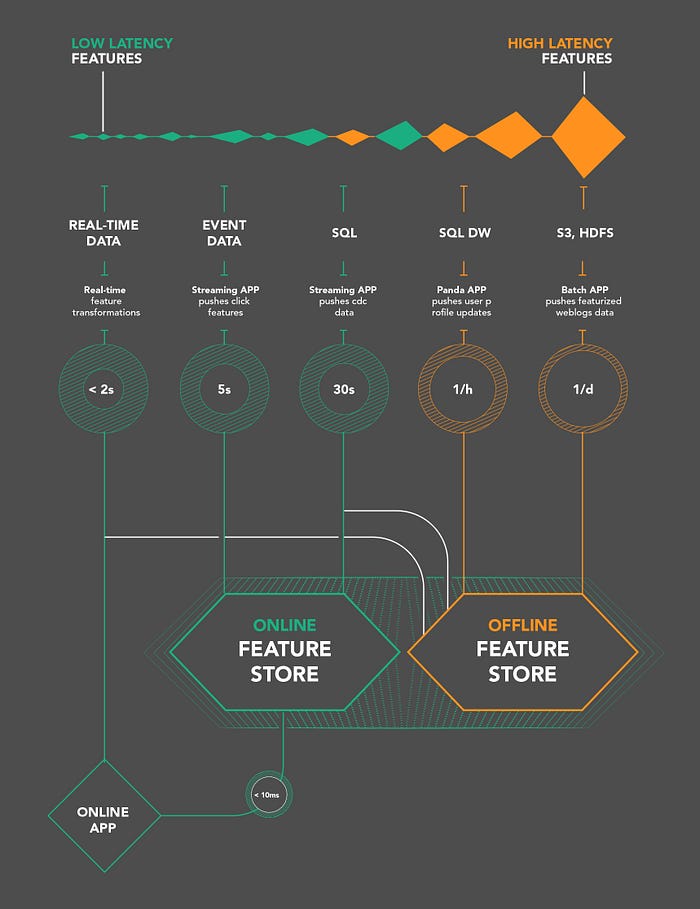
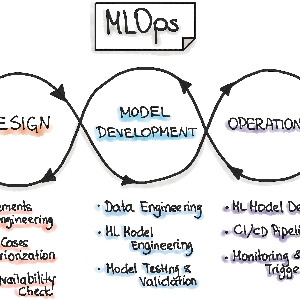
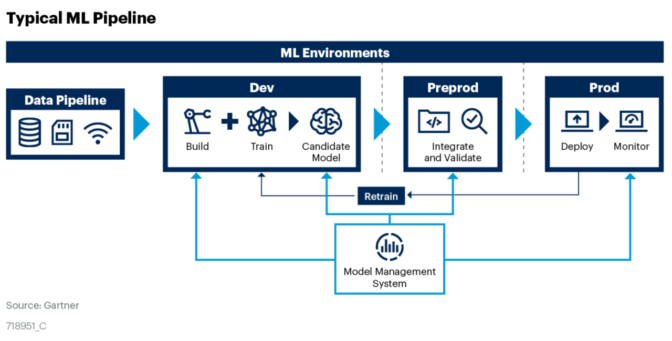
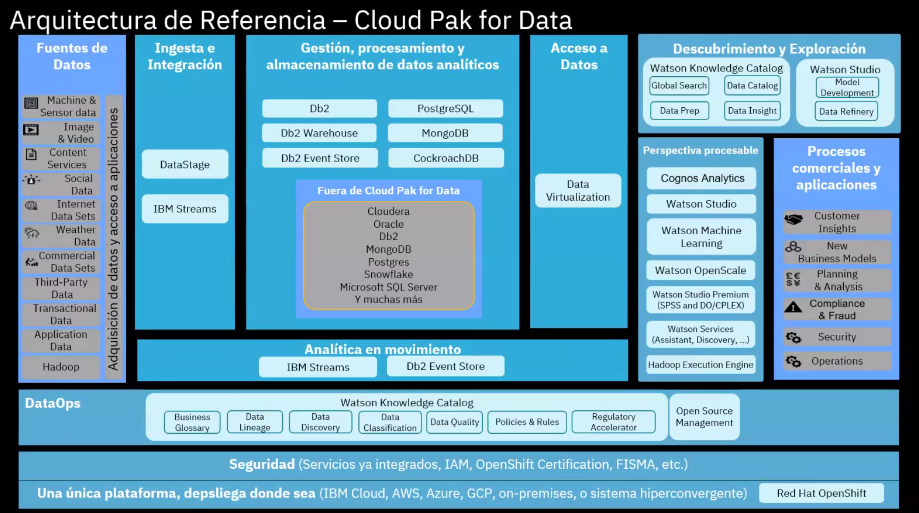
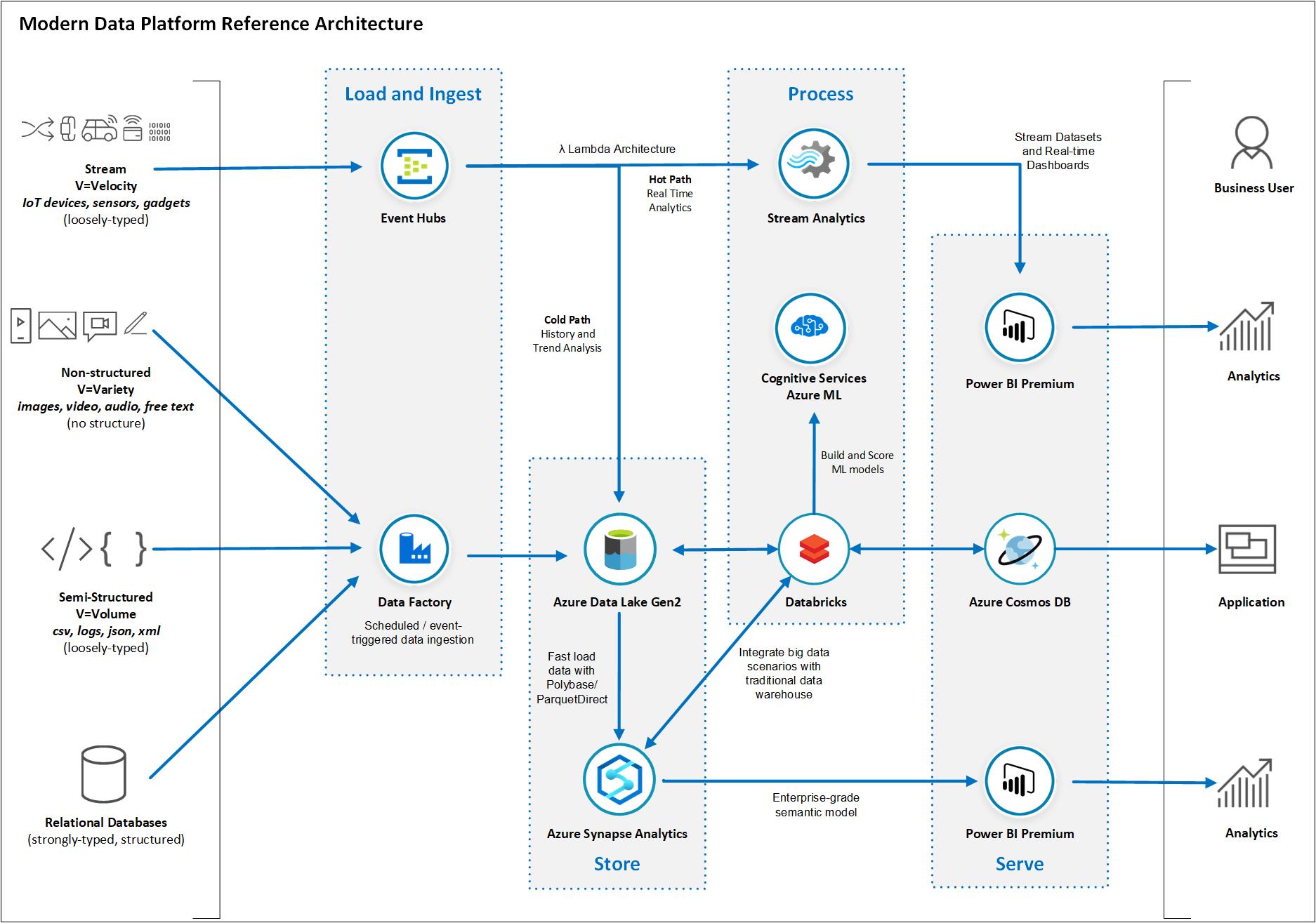
La transformación digital afecta a todas las áreas de negocio, incluida la innovación de productos, las operaciones, la estrategia de comercialización, el servicio al cliente, el #marketing y las #finanzas.
Sin embargo, la digitalización no se trata solo de acelerar los procesos comerciales y aprovechar nuevas oportunidades. También se trata de la necesidad de superar la disrupción digital y solidificar la posición de uno en un entorno empresarial en rápida evolución.
Para identificar qué áreas necesitan ser transformadas y cómo, para eliminar los posibles riesgos y evitar el drenaje innecesario de recursos, las organizaciones modernas adoptan el enfoque basado en datos para la transformación digital. Usan ciencia de datos, #bigdata, #machinelearning, #BI para recopilar, procesar y analizar sus datos comerciales, que luego pueden convertir en información procesable.
Las últimas encuestas indican que la conectividad e integración de datos se consideran componentes críticos para la transformación digital en la mayoría de las empresas.
En este caso, #DSaaS (la ciencia de datos como servicio) puede desempeñar un papel crucial para ayudar a transformar digitalmente su negocio y aumentar el #ROI.
¿CÓMO FUNCIONA DSaaS?
DSaaS es principalmente un modelo de servicio basado en la nube, donde se proporcionan diferentes herramientas para el análisis de datos y el usuario puede configurarlas para procesar y analizar enormes cantidades de datos heterogéneos de manera eficiente.
Los clientes disponibilizarán los datos de la empresa en la plataforma DSaaS y obtendrán información analítica de valor. Estos conocimientos analíticos son producidos por aplicaciones, que armonizan los flujos de datos creados a partir de la utilización de servicios que generan los algoritmos. Una vez que los clientes cargan los datos en la plataforma, el DSaaS se puede incorporar con ingenieros de datos que trabajarán en los datos cargados.
En su mayoría, existen modelos basados en suscripción. También se puede generar una entrega meticulosa de modelos predictivos listos para producción y análisis de datos utilizando otras metodologías.
HABILITACIÓN DE LA TOMA DE DECISIONES BASADAS EN DATOS
Dado que la transformación digital es un proceso complejo, los datos sobre sus clientes y las operaciones comerciales pueden ayudarlo a tomar decisiones informadas y, al mismo tiempo, evitar riesgos innecesarios.
Con las capacidades de ciencia de datos, puede identificar cómo transformar digitalmente su negocio y qué áreas comerciales requieren transformación. Al mismo tiempo, la ciencia de datos como servicio permite a las empresas contratar a un proveedor profesional que tiene los recursos necesarios y puede ayudarlo a implementar esta transformación más rápido, manteniéndolo por delante de la competencia.
No es de extrañar por qué cada vez más organizaciones están adoptando la ciencia de datos como un servicio para acceder a un enorme grupo de expertos en datos para mejorar su toma de decisiones. En consecuencia, las empresas, pueden generar un impacto en su estrategia y operaciones digitales, ya sea en forma de aumento de ingresos, reducción de costos o eficiencias mejoradas.
Con DSaaS, la inteligencia del cliente ahora está tan optimizada y accesible en todos los niveles de la organización como sea posible. Por lo tanto, incorporar e inculcar la ciencia de datos como un servicio en los procesos de toma de decisiones es esencial para obtener los resultados y beneficios deseados de las tecnologías digitales.
IDENTIFICAR AMENAZAS Y OPORTUNIDADES
El volumen de información disponible está creciendo rápidamente junto con las oportunidades que abre. La ciencia de datos como servicio permite a las organizaciones hacer frente a la escasez de científicos de datos y aprovechar la ciencia de datos para obtener una vista más panorámica y detallada de su entorno empresarial.
La ciencia de datos está habilitando la próxima generación de soluciones que pueden predecir lo que sucederá y cómo evitarlo. Por ejemplo, imagine tener una aplicación CRM con la capacidad de pronosticar qué clientes tienen más probabilidades de realizar la próxima compra, qué productos serán parte de esa compra y qué clientes están en riesgo de desgaste.
Las soluciones habilitadas por la ciencia de datos permiten a las empresas de diversas industrias tener visibilidad en tiempo real de sus clientes, lo que ayuda a los tomadores de decisiones a optimizar las operaciones internas para una mayor agilidad, mayor flexibilidad y menores costos.
¿CÓMO MONETIZAR LOS DATOS?
Las empresas a menudo se sienten confundidas y escépticas cuando llega el momento de monetizar sus datos. Casi todo el tiempo, no saben cómo hacerlo.
Sin embargo, la ciencia de datos como servicio puede ayudar a una empresa a monetizar sus datos mediante un análisis profundo en una revisión de producto, quién lo compraría y por qué razones. Por eso se realizan encuestas para recolectar una muestra de datos, que es una herramienta para fabricar sus estrategias de marketing. Después de tales encuestas, las herramientas de análisis de datos ilimitadas disponibles para crear ideas útiles.
Este proceso también ayuda a una empresa a comprender la necesidad de su producto y cuánto debe lanzarse al mercado en un momento dado (incluso antes de lanzar el producto).

WRAP-UP
DSaaS es una opción ideal para que las empresas administren sin un gran equipo de científicos y analistas de datos internos. Proporciona a las empresas acceso a recursos de análisis para demandas particulares de ciencia de datos sin mucho gasto en la creación de dichos equipos desde cero.
Aprovechar todo el potencial de las tecnologías y los datos innovadores requiere desarrollar una estrategia eficaz de ciencia de datos. DSaaS presenta enormes oportunidades al permitir a las empresas aprovechar fácilmente los datos para tomar mejores decisiones, operar de manera más eficiente y rentable, ofrecer experiencias más personalizadas y mejorar la calidad general de los servicios.
Por lo tanto, las empresas ya no tienen que depender de conjeturas, ya que la ciencia de datos puede ayudar a hacer predicciones más concretas cuando fallan tanto la intuición humana como la experiencia. La clave para aprovechar estas oportunidades radica en nuestra capacidad para introducir sin problemas la ciencia de datos en los procesos de transformación digital de su empresa.