Ya nadie discute que los nuevos negocios dentro de las compañías, nacen aprovechando toda la informacion que guardaron estos años, y son esos datos los que permite crear nuevos productos, nuevos negocios, conocer mas a los clientes.
Pero también es necesario mencionar que se tiende a simplificar el “como” se usan esos datos. Los datos aportan valor si son confiables y de calidad, y para ello es necesario conocer su contenido y estructura.
En esta nota vamos a mencionar el camino recomendado para adoptar soluciones de #InteligenciaArtificial en la analítica partiendo desde una metodología de #gobernanza que asegure la calidad de los datos.
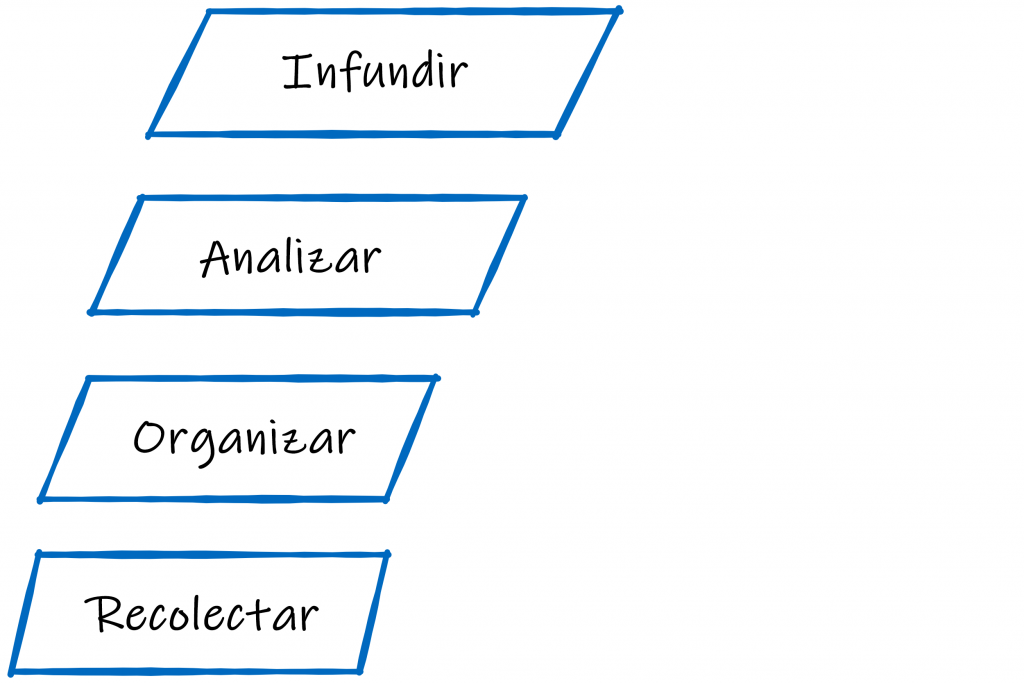
La fase de Recolección de Datos
El primer desafío es Recolectar la informacion que poseen las empresas, y en este sentido el desafío principal pasa por realizar una modernización de los procesos y flujos, para identificar todos aquellas bases de datos, tablas, archivos que tenemos a disposición para consumir esa informacion.
La fase de Organización de Datos
El segundo punto es Organizar esa informacion, generando un lenguaje común, para que todos los usuarios (de negocios y TI) conozcan todos los datos que estamos manejando, que exista una relación entre el lenguaje comercial y el lenguaje técnico; donde podamos generar Dueños de Datos. Estos Dueños de Datos (data stewardship) es lo que nos va a permitir la gestión y supervisión de los activos de datos de nuestra organización para ayudar a proporcionar a los usuarios comerciales datos de alta calidad.
Estos niveles de calidad son fundamentales si queremos tener reportes fidedignos; y por tal motivo vamos a correr procesos de Curación, Gestión de Metadatos, Linaje y Catalogo, entre otros procesos que serán los que dejaran lista una base de datos lista para el negocio.

La fase de Análisis de Datos
La fase de Organización nos va a permitir saltar a la fase de Análisis, donde vamos a poder armar #Dashboards y #Reportes desde informacion confiable, y eso se va a permitir:
- Encontrar: Acceso mas rápido a la informacion
- Confiar: Entender de donde provienen los datos y porque se puede confiar en ellos
- Preparar: Limpiar, estructurar y enriquecer datos crudos para transformarlos en informacion procesada
- Actuar: Generar nuevos resultados comerciales desde Análisis mas confiables.
Infundir: la capa de análisis inteligente
Luego de haber creado una plataforma de integración robusta, de tener identificado nuestros datos como activos y de generar reportes confiables, vamos a implementar una capa de Analítica Avanzada, donde logremos descubrir tendencias y patrones que mejoren la toma de decisiones mediante técnicas de exploración cognitiva.
En este punto soluciones de #MachineLearning logran destrabar el valor de los datos, permitiendo generar nuevos productos basados en el reconocimiento 360° de los clientes, detectar necesidades de la industria o simplemente lograr identificar cosas que siempre estuvieron invisibles a un análisis tradicional.
Que arquitecturas nos proponen los vendors?
Existe un consenso de la industria en torno al armado de arquitecturas de datos en distintas capas. La gran mayoría son plasmadas en gráficos que se pueden “leer” de izquierda a derecha, conformados por:
- Capa Fuentes de Datos: donde contamos con los orígenes de datos, estos orígenes pueden ser bases de datos, webs, archivos, eventos, sensores, etc.
- Capa de Integración: desde donde se efectúa el comportamiento relacionado a la orquestación del movimiento, transformación e ingesta de los datos.
- Capa de Procesamiento: donde se ejecutan los procesos analíticos, ya sea en cubos.
- Capa de Visualización: donde finalmente se presentan de forma amigable lo referido a reportes de cara a los usuarios.
A continuación veamos algunos esquemas de alto nivel que proponen #IBM y #Microsoft.
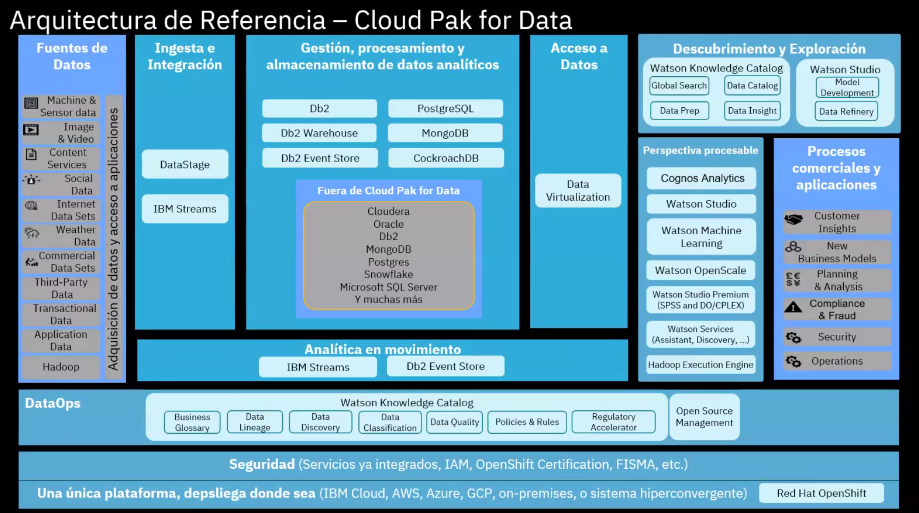
Arquitectura de Data provisto por IBM
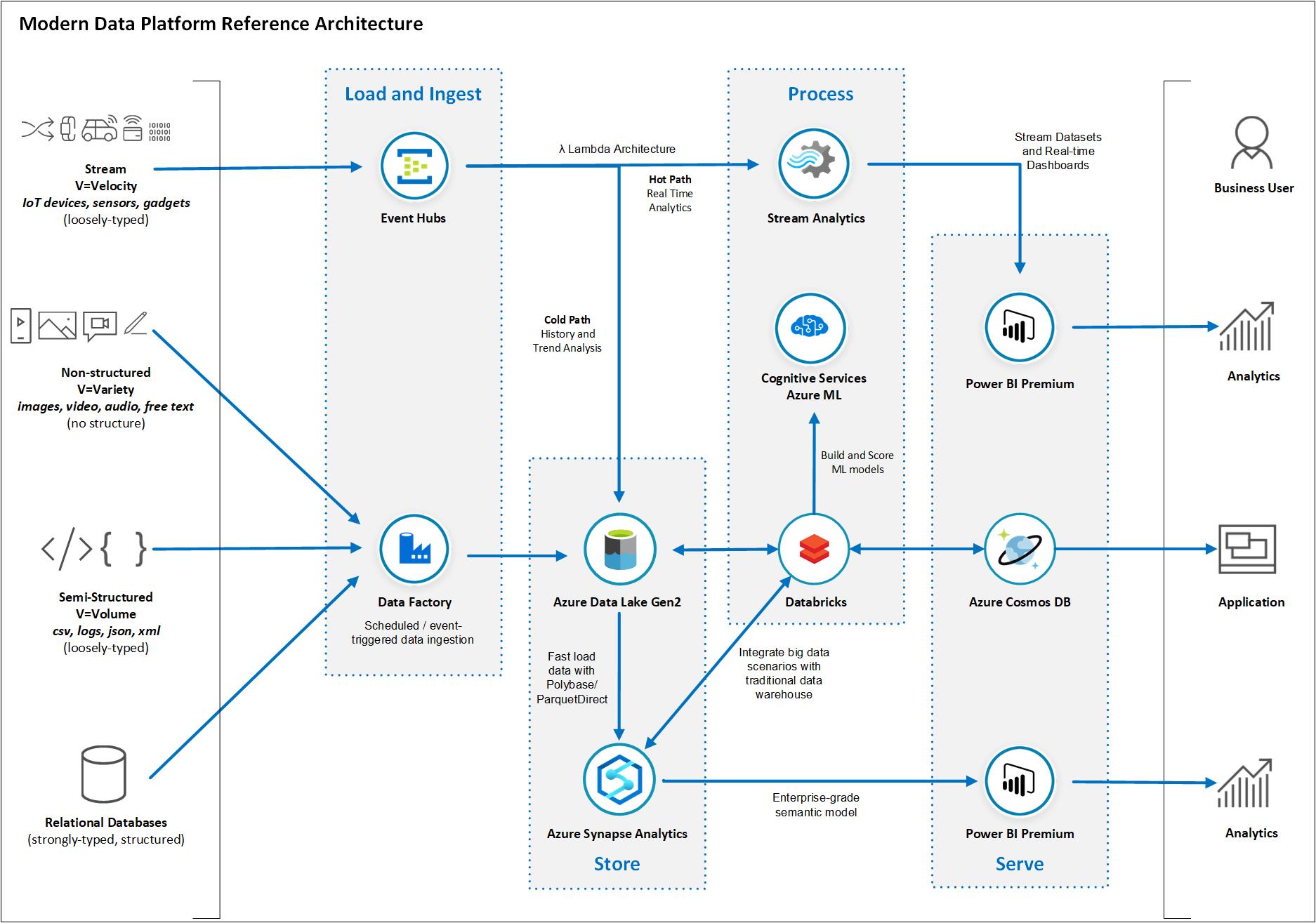
Arquitectura de Data provisto por Microsoft en Azure
Conclusiones finales
Las tecnologías de análisis están al alcance de la mano de todos. En los últimos años, el crecimiento de la generación de datos es exponencial y lo seguirá siendo; y en paralelo las tecnologías cloud generaron una disminución en el costo del storage, mayor procesamiento, consumo “por uso” y aplicaciones apilables que nos permiten desarrollar una plataforma en la nube con muy poco esfuerzo.
Pero el mayor valor de una plataforma de datos no esta dado por la tecnología sino por los requerimientos de negocios que resolvemos.
Desde #54cuatro alentamos a nuestros clientes a convertirse en empresas inspiradas por los datos, donde la informacion sea un catalizador de nuevas ideas; y es por eso que no hacemos recomendaciones tecnológicas sin entender los requisitos, porque nosotros ofrecemos practicas y metodologías de gestión de datos (que entre otras cosas incluye el factor tecnológico) donde el mayor valor del análisis se da cuando se gestiona la informacion como un asset y donde la calidad asegura que los reportes mejoren la toma de decisiones, el servicio al cliente y el ROI.
| [popup_anything id=”2076″] |