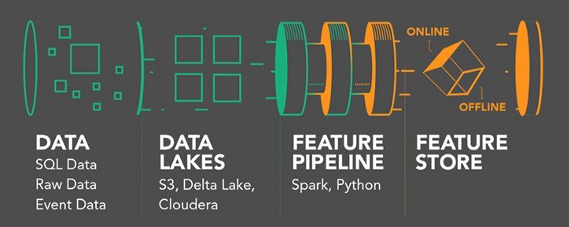
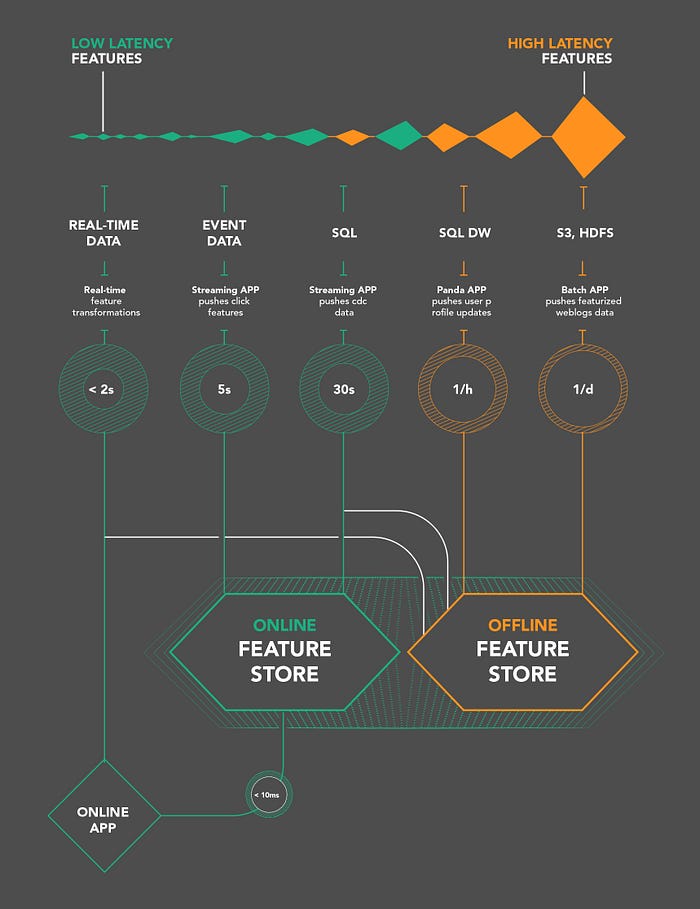
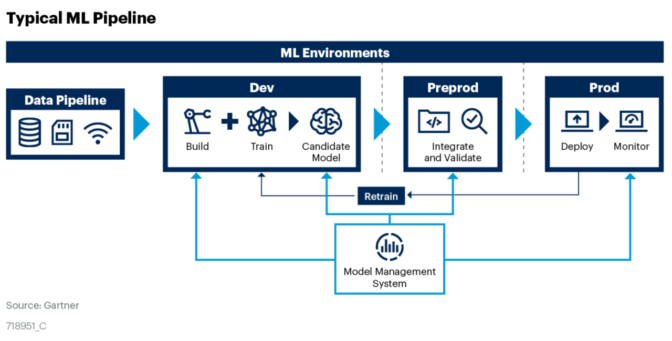
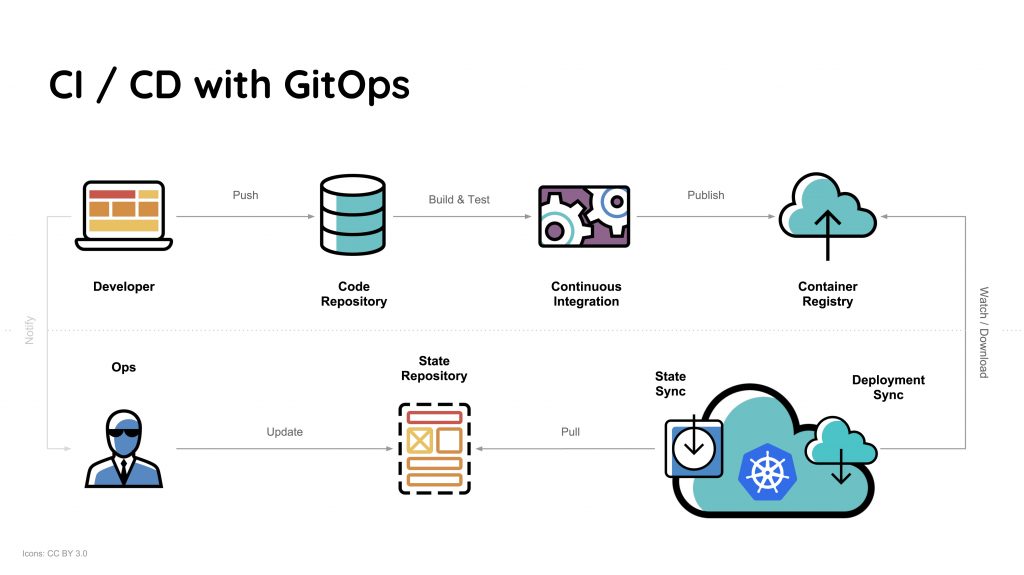
Una tecnología disruptiva o una innovación disruptiva es una innovación que ayuda a crear un nuevo mercado y una nueva red de valor y, finalmente, continúa alterando una red de mercado y valor existente.
¿Porque fallan los proyectos?
En la actualidad 1 de cada 10 proyectos relacionados con #IA logra tener éxito. El éxito no esta medido por el cumplimiento de las implementaciones, sino por el valor que se logra de cara al negocio.

Las fallas en este tipo de proyectos (en nuestra experiencia) vienen dados por 2 puntos:
- Falta de colaboración entre las áreas para lograr una solución que aporta valor.
- No tener los datos adecuados.
¿Cómo mitigar los riesgos?
En #54cuatro tenemos una #metodología que permite a nuestros clientes ir logrando un nivel de madurez que asegure el éxito de los proyectos de #InteligenciaArtificial.
Esa metodología denominada #Metolodogia54, busca lograr convertir a los clientes hacia empresas #DataDriven, afectando sus capacidades en cuanto a factores Culturales, Procesos y Tecnología en pos de asegurar la creación de sinergias entre los grupos de trabajo y obtener (o crear) los datos adecuados.
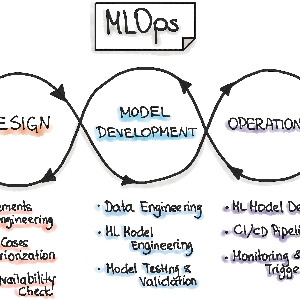
Tendencias en boga como #MLOPS son buenas alternativas para optimizar proyectos de #MachineLearning y aproximarse con mayor seguridad al éxito buscado, pero además es importante que todas las personas de la organización estén comprometidas a buscar el éxito, dado que los proyectos IA son 100% colaborativos es fundamental considerar los datos que se tienen disponibles y los conocimientos que se pueden obtener de ellos pero es aun mas necesario considerar el nivel de apoyo de la gerencia u organización en general y finalmente establecer expectativas realistas en torno a lo que la #IA ayudará a resolver.
Medición de resultados
Con las expectativas marcadas como hito a cumplir, es necesario generar una adecuada medición de resultados. El personal técnico suele medir el resultado de un modelo de datos por como “performa” ese modelo (Precision, Recall, F1, etc). Ese es un grave error que genera desconfianza en lo que se esta realizando. En su lugar, es preferible establecer hitos de éxito medibles en los términos más importantes para la empresa, como eficiencia operativa, aumento de ventas o de ahorro de costos.

Algunas otras veces, se espera un nivel mínimo de resultados de cada modelo, sin embargo es bueno participar a gente de áreas de negocio mientras se realizan los desarrollos para que puedan probar y comparar el rendimiento, realizar sugerencias y complementar el modelo con las fortalezas (y debilidades) de los expertos ‘humanos’.
En modelos predictivos, crear un ciclo de retroalimentación permite mejorar el reentrenamiento para que su modelo pueda incorporar rápidamente nuevos puntos de datos y dar como resultado un aumento y mejora de las predicciones futuras.
Conclusión
Los proyectos basados en tecnología disruptiva generan grandes expectativas pero para poder cumplir con lo que se espera, es necesario comprometer a la organización en pos de lograr buenas fuentes de datos y poder trabajar con los científicos de datos a medida que se generan soluciones de negocio, retroalimentando los desarrollos con experiencia de las personas.