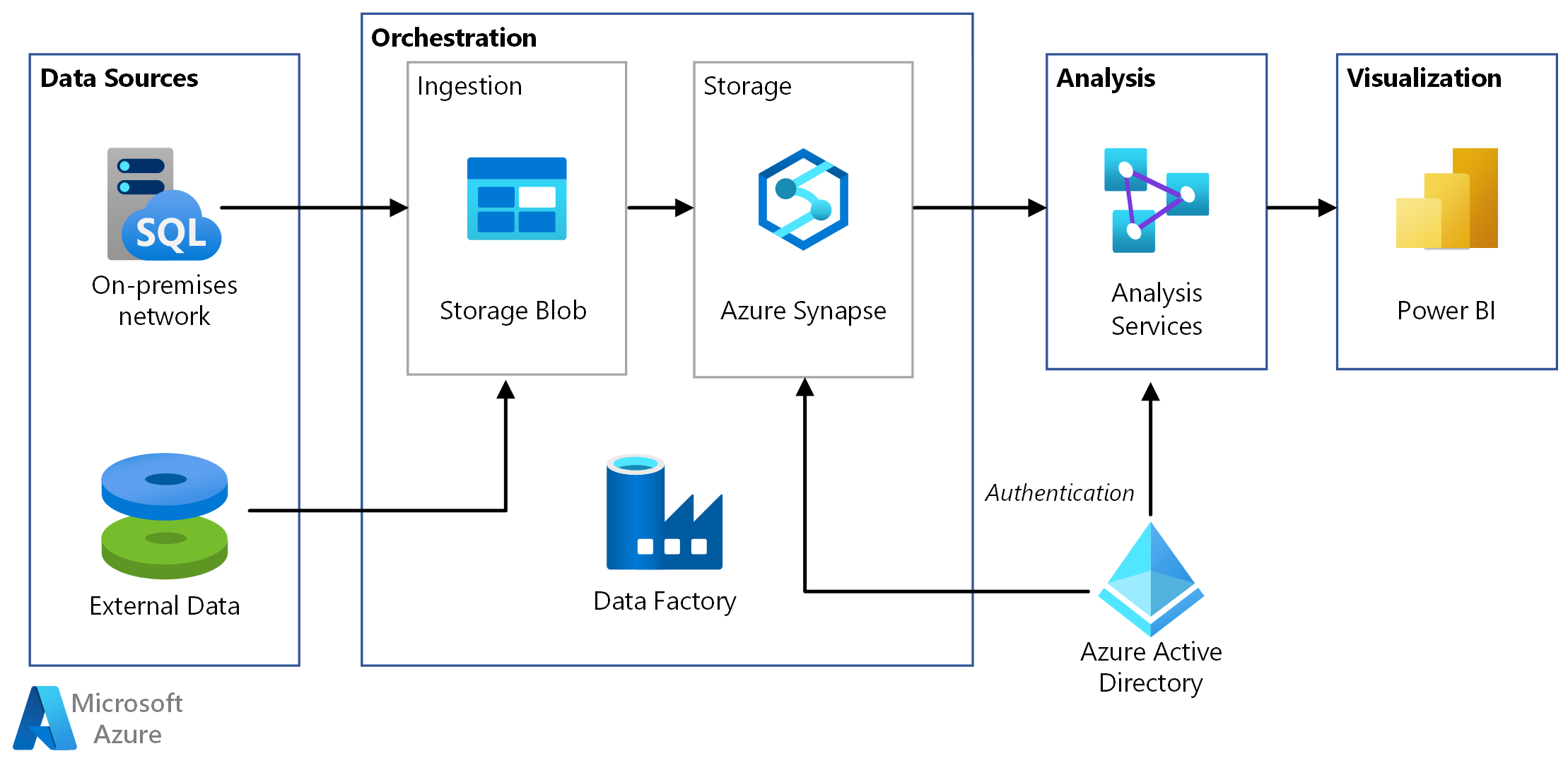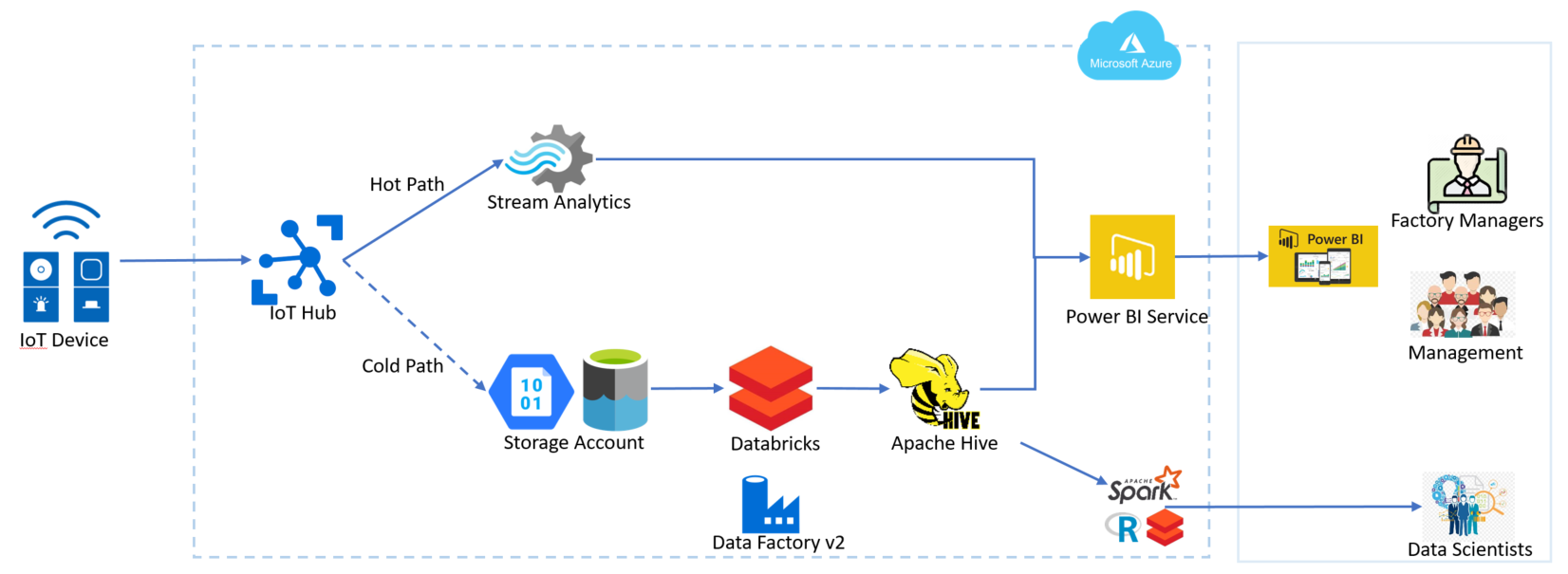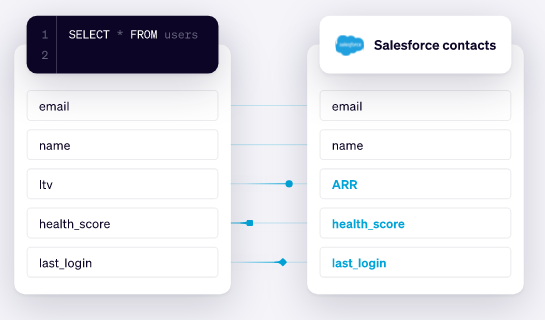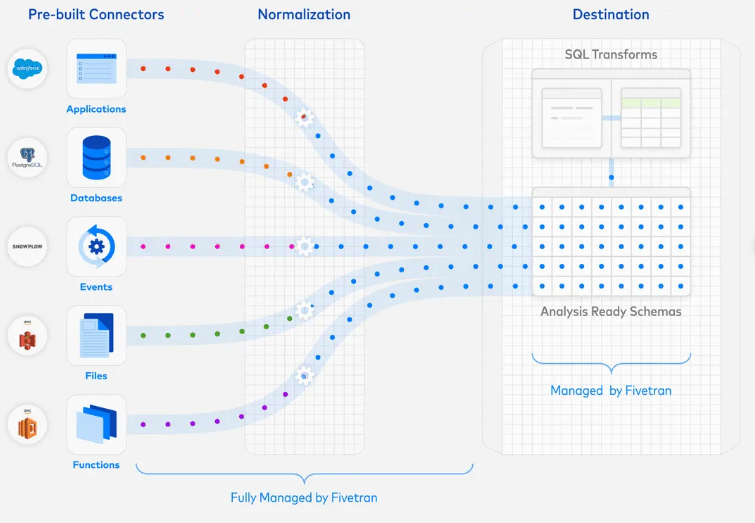
Quienes trabajamos como #EnterpriseArchitect sabemos de la necesidad de documentar lo que vamos creando. Necesitamos herramientas UML para poder bajar a detalle y crear un esquema visual de lo que luego se convertirá en un producto.
¿Qué es #UML?
UML es una técnica para la especificación sistemas en todas sus fases, un lenguaje para hacer modelos y es independiente de los métodos de análisis y diseño.
Nació en 1994 cubriendo los aspectos principales de todos los métodos de diseño antecesores y, precisamente, los padres de UML son Grady Booch, autor del método Booch; James Rumbaugh, autor del método OMT e Ivar Jacobson, autor de los métodos OOSE y Objectory.
¿Cuales son las herramientas de UML?
Existen algunas herramientas tradicionalmente usadas para este tipo de trabajos. Tradicionalmente el #Visio de #Microsoft es de las más referenciadas.
En la actualidad existen muchas nuevas herramientas, algunas web, algunas open source, que permiten realizar el modelo de Arquitecturas Aplicativas o de IT en general.
El gran auge de la #nube, creó un sinfín de nuevas herramientas de modelado, algunas específicas para cada nube, como el caso de Cloud Craft que permite crear modelos basados en tecnología #AWS, y que además permite conectarse a la calculadora de #Amazon para realizar el presupuesto de lo que está definiendo.

Sin dudas es una herramienta súper potente. Siguiendo dentro de la misma familia, existen algunas como Cloud Skew o Hava que nos permiten realizar el diseño no solo para AWS sino también para #Azure o #GCP.
Modelando en la web
No podemos dejar pasar por alto herramientas de mucha utilidad como LucidChart o Draw.io (ahora renombrada como Diagrams.net), que no solo son de utilidad para Arquitectos, sino para generar todo tipo de gráficos anidados con cierta lógica como Flujos de Procesos u Organigramas, como para mencionar algunos ejemplos.
Nuestra preferida: Archimate
Nuestra preferida es sin dudas #Archimate. Es quizás la herramienta hecha por y para Arquitectos Empresariales o Enterprise Architects, bajo el estándar abierto propuesto por Open Group.
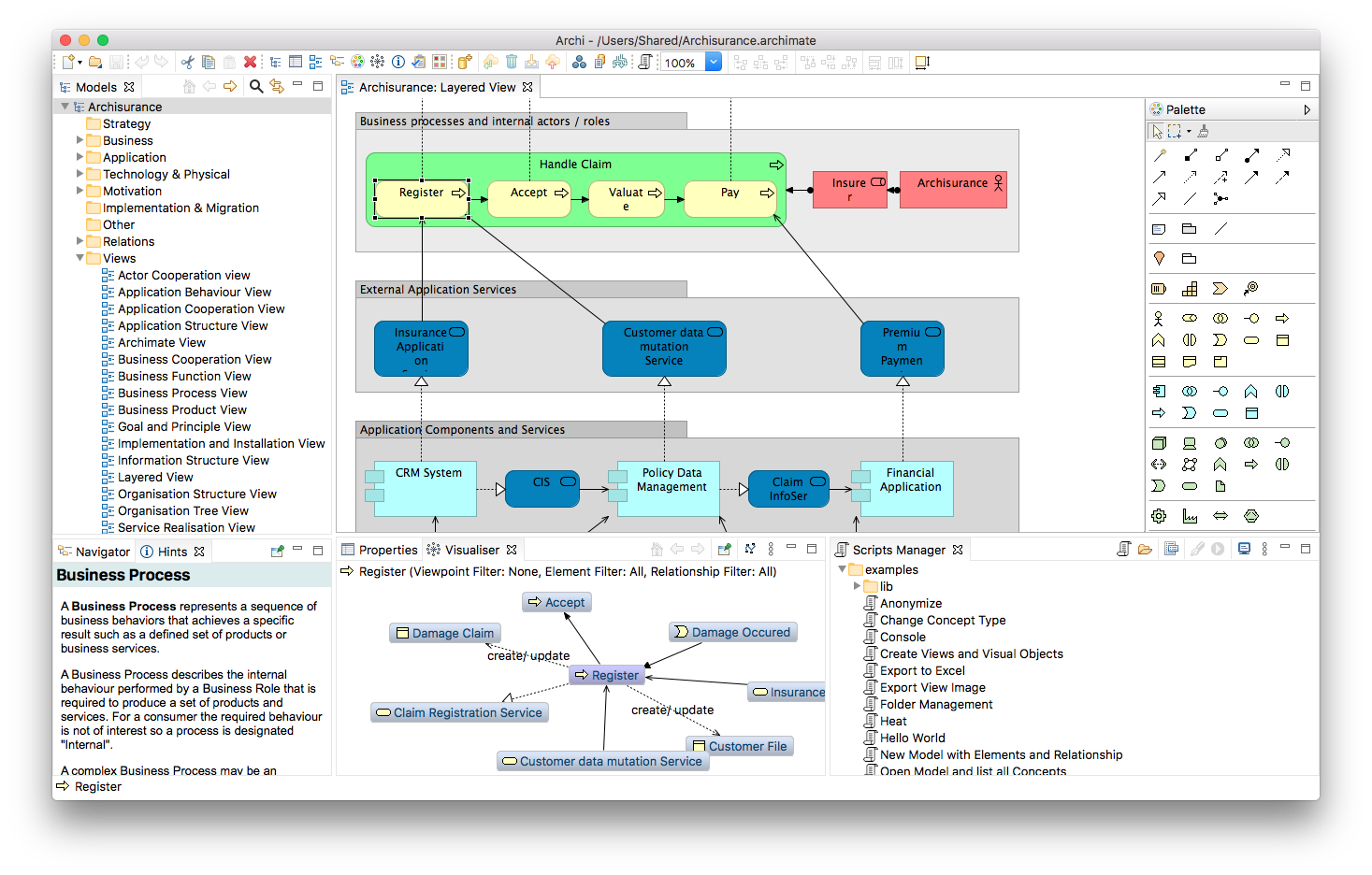
Archimate es una herramienta #OpenSource, que puede ser usada en #Windows, #Linux y #Mac, y que puede ser descargada desde la web archimatetool.com. Permite a los usuarios de esta tool, crear modelos basados en frameworks de arquitectura como #TOGAF. Dentro de una misma aplicación se pueden crear flujos de negocios, modelos de planificación de tipo Mind Mapping, modelos de interrelación aplicativa, y hasta planificaciones basadas en #Agile.
Sin dudas es la elegida por nuestro equipo, y la que recomendamos para llevar a cabo las tareas de planificación inherentes a un arquitecto.
¿Y tu equipo, qué herramienta utiliza?
| [popup_anything id=”2076″] |