Acerca de la arquitectura Sin Servidor
Hace un tiempo hicimos una entrada respecto a patrones de arquitectura para microservicios, la cual tuvo gran repercución, motivo por el cual traemos esta entrada referente a la arquitectura serverless.
Cuando hablamos de arquitectura serverless o “sin servidor” nos referimos a diseños de aplicaciones que utilizan un Backend como Servicio de terceros (ej, Auth0) o que incluyen código propio que se ejecuta en contenedores efímeros administrados por un tercero, en plataforma que denominamos “funciones como servicio” (FaaS).
Lógicamente estos contenedores son auto-administrados por el proveedor, en general Cloud Providers, pero de cara al cliente una plataforma serverless evita tener que gestionar infraestructura en su formato tradicional.
Existen aplicaciones para lograr correr Serverless on-premise, proyectos como Fission o Kubeless, permiten armar la infraestructura sobre Kubernetes; pero el gran crecimiento de estas soluciones esta dado por los proveedores como #AWS, #Azure y #GCP.
FaaS que delega un parte de la arquitectura en Backend como Servicio (#BaaS)
Este tipo de arquitectura en gran parte esta siendo impulsada por los microservicios, permitiendo generar una reduccion significativa de las ingenierias, delegando muchas partes de la arquitectura en terceros. Por ejemplo:
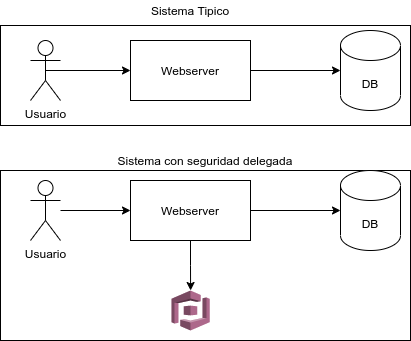
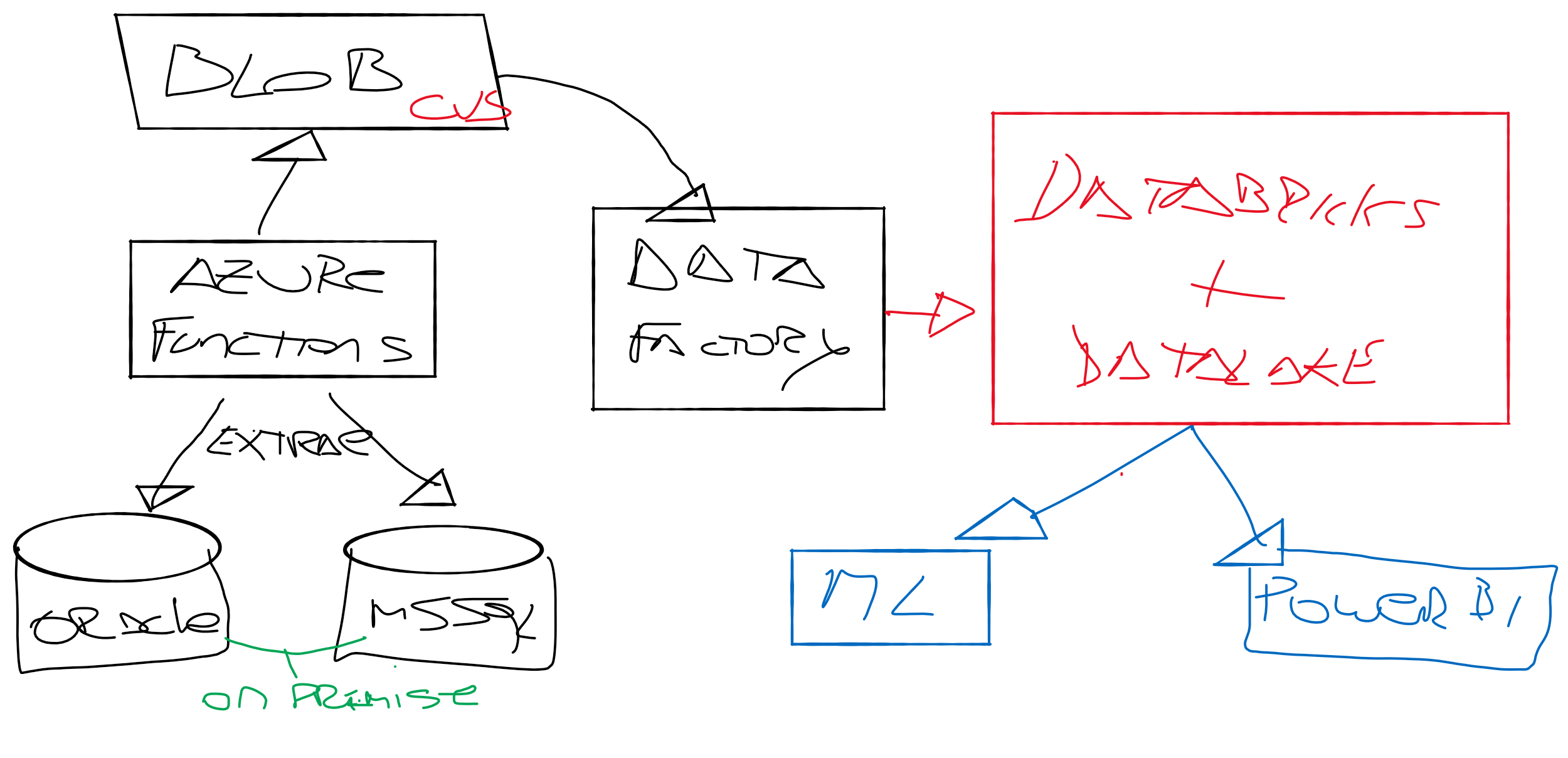
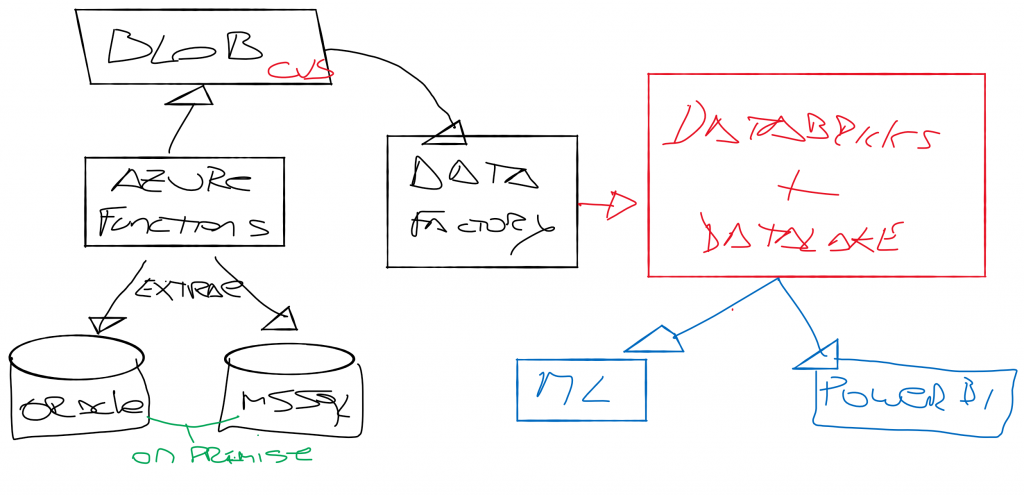
En el gráfico podemos observar un sistema típico de autorización/autenticación de un sitio web en un formato tradicional con los usuarios generados en la misma base de datos operativa, contra un sistema que delega la autorización/autenticación en un sistema de un tercero (#AWS #Cognito en el ejemplo). En el ejemplo tenemos 2 patrones. La validación de usuarios pasa a ser un microservicio, y su funcionamiento es completamente delegado a un tercero que nos brinda su backend como un servicio. En lineas generales la arquitectura de microservicios requiere de la creación de un #API gateway.
Pero sigamos avanzando y veamos otro formato de #FaaS o Serverless.
El otro formato al que se suele hacer referencia cuando se menciona #serverless se trata de ejecutar código backend sin administrar servidores y las corridas se efectúan durante un periodo de tiempo. En este caso, el código que uno realiza, es ejecutado por una plataforma de terceros, básicamente cargamos el código de nuestra función al proveedor, y el proveedor hace todo lo necesario para aprovisionar recursos, instanciar VM, crear #containers, administrar procesos, y ademas de gestionar la performance y asegurar los servicios. Las #funciones en FaaS generalmente se activan mediante tipos de eventos. Ej: recibir una petición http, detectar un objeto en un storage, tareas programadas manualmente, mensajes (tipo MQ), etc.

Precaución con el concepto de Stateless o Sin estado
Se suele decir que las FaaS son #stateless o “sin estado”. Este concepto hace referencia a que al ser código que se ejecuta de forma efímera, no existe almacenamiento disponible, de manera que cualquier función que requiera mantener persistencia debe externalizar la persistencia fuera de instancia FaaS. En Stateless cada operación se realiza como si se está haciendo por primera vez. Cuando una función requiere persistencia debemos acudir a capas adicionales de infraestructura como bases de datos de caché, bases de datos relacionales y/o storages de archivos y objetos y de esa forma pasamos a ser #stateful, lo que significa que se controla la historia de cada transacción pasada y que ellas pueden pueden afectar a la transacción actual.
Tiempo de ejecución
Otro concepto importante cuando hablamos de serverless tiene que ver con el tiempo de ejecución de las funciones. En la arquitectura sin servidor, las funciones suelen estar concatenadas y orquestadas donde cada tarea es dependiente de otra, y esto hace que si alguna se demora o falle, pueda afectar toda la sincronización configurada. Este motivo es suficiente para determinar que funciones de larga duración no son apropiadas en este modelo.

En linea con esto, existe otro concepto llamado “arranque en frío” y que tiene que ver con el nivel de respuesta de una función ante su desencadenador.
Como mencionamos, el desencadenador o trigger es lo que dispara la ejecución de una función y la función luego se ejecuta durante un periodo de tiempo determinado, esto hace que aplicaciones con muchas lineas de código, que llaman librerías, o cualquier motivo que genere que el inicio sea “pesado”, no sean recomendables para entornos FaaS.
Ventajas y Desventajas de FaaS
Sin dudas adoptar serverless es algo que esta de moda, y que trae sus grandes ventajas. En la parte de arriba hemos recorrido grandes ventajas y hemos detectado situaciones donde no es conveniente usar funciones. Pero como resumen podemos resaltar que trae grandes ventajas a nivel costos, dando como resultado una fuerte reducción de los mismos. Adicionalmente permite optimizar ejecuciones y simplificar gran parte de la administración de infraestructura requerida para ejecutar código.
En contrapartida, la arquitectura serverless requieren de cierta maduración por parte de los desarrolladores (y sus productos) ya que todo el despliegue se debe hacer bajo modelos CI/CD en lo que actualmente se esta dando a conocer como #NoOps (voy a patentar el termino YA*OPS, yet another * ops :)) donde se busca poder ir a producción sin depender de un equipo de Operaciones.
Y finalmente, es importante mencionar que al subir código a proveedores de nube se genera un alto nivel de dependencia sobre ellos, algo poco recomendado claramente.
Patrones de arquitectura
Es el titulo de la nota, pero hasta ahora no hicimos foco sobre patrones. Los patrones de arquitectura serverless aun no tiene un marco definido. Lo que se viene delimitando como mejores practicas tiene que ver con temas a considerar previo a crear una plataforma serverless. Por ejemplo:
- ¿Cuantas funciones se crearán?
- ¿Que tan grandes o pesadas serán?
- ¿Como se orquestarán las funciones?
- ¿Cuales serán los disparadores de cada función?
Gran parte de la estrategia serverless viene adoptada de las arquitecturas de microservicios y de eventos; y en gran parte los conceptos ‘Event Driven’ y ‘API Driven’ conforman el núcleo de arquitecturas serverless. Y esto hace que también debamos preguntarnos:
¿Como generamos una arquitectura híbrida que considere API, Funciones, PaaS, IaaS, etc.?
La CNCF y los proveedores de nube vienen trabajando a gran velocidad para responder estas consultas y establecer un marco arquitectónico a considerar, algo que será muy bienvenido por todos, ya que nos permitirá tener referencias por ejemplo para lograr neutralidad sobre dónde y cómo implementar nuestras apps sin caer indefectiblemente en el ‘vendor lockin’ o como generar una estrategia multicloud en arquitecturas FaaS.
Conclusión
Durante la nota explicamos ventajas, desventajas y consideraciones en cuanto a montar servicios corriendo serverless. Sin dudas es una tendencia que cada día crece mas y se encuentran nuevos beneficios. En nuestra consideración permite crear grandes productos, pero siempre hablando de productos digitales nuevos, no creemos que refactorizar aplicaciones existentes y/o migrar a serverless sea hoy una estrategia viable. No es imposible, pero si algo arriesgado. La recomendación es comenzar con piezas pequeñas, integraciones y ejecuciones controladas. Para otro tipo de aplicaciones mas complejas, los esquemas de microservicios sobre contenedores son una buena alternativa a la que incluso aun les queda mucho por recorrer.
Si esta pensando en trabajar con serverless y necesita ayuda, escribanos desde el siguiente formulario:
| [popup_anything id=”2076″] |