Desafío planteado
El cliente nos indica que tiene 2 bases de datos, una Oracle 11g y otra MSSQL2016 donde se guarda informacion de dos sistemas corporativos de tipo BSS, y ademas junto con esa data necesitaban enriquecer la info con algunos archivos que reciben en formato CSV de algunos proveedores, y que para poder analizarlos ejecuta algunos procesos manuales, suben todo a una base de datos intermedia y desde ahí hacían tableros de BI.
Este proceso corría una vez por dia, involucraba la participación de una persona y no cumplía con los tiempos requeridos por el negocio.
Nuestro cliente quería evaluar cuidadosamente si nuestra propuesta de inteligencia empresarial hacia sentido para ellos, motivo por el cual propusimos hacer este desarrollo como PoC (prueba de concepto), sin involucrar el armado de un datawarehouse ya que contaban con uno on-premise y tampoco quería instalar servidores ni adquirir nuevas licencias, de manera que teníamos que desarrollar una solución consumiendo de servicios de Nube.
Solución Propuesta
Durante la charla propusimos hacer uso de servicios serverless en la nube, Funciones en #AWS o #Azure, donde un script se ejecute para extraer la info, procesarla y dejarla disponible para analizar. Una especie de #ETL #serverless.
Otra alternativa era armar una infraestructura de eventos con #Kafka o #NiFi. Pero como la solución tenia que ser bajo la premisa de no instalar equipamiento finalmente desistimos de esta opción.
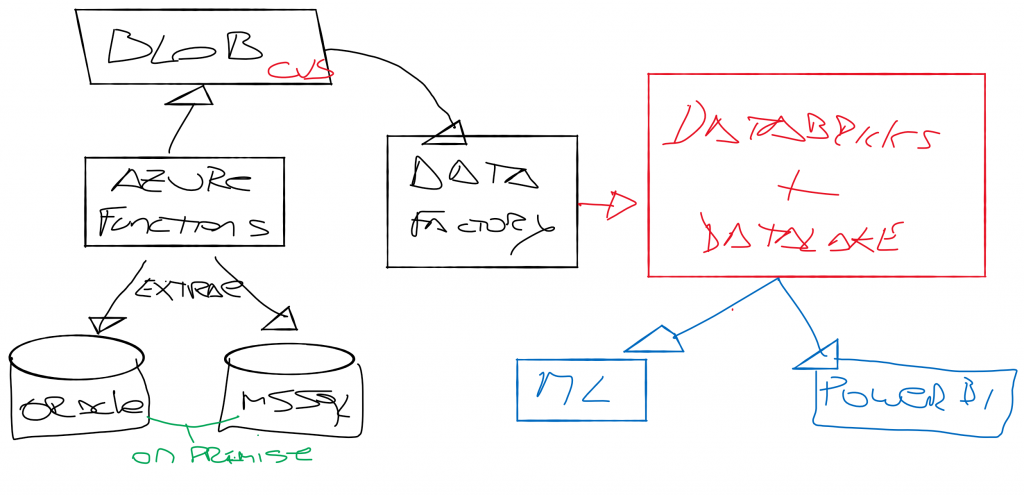
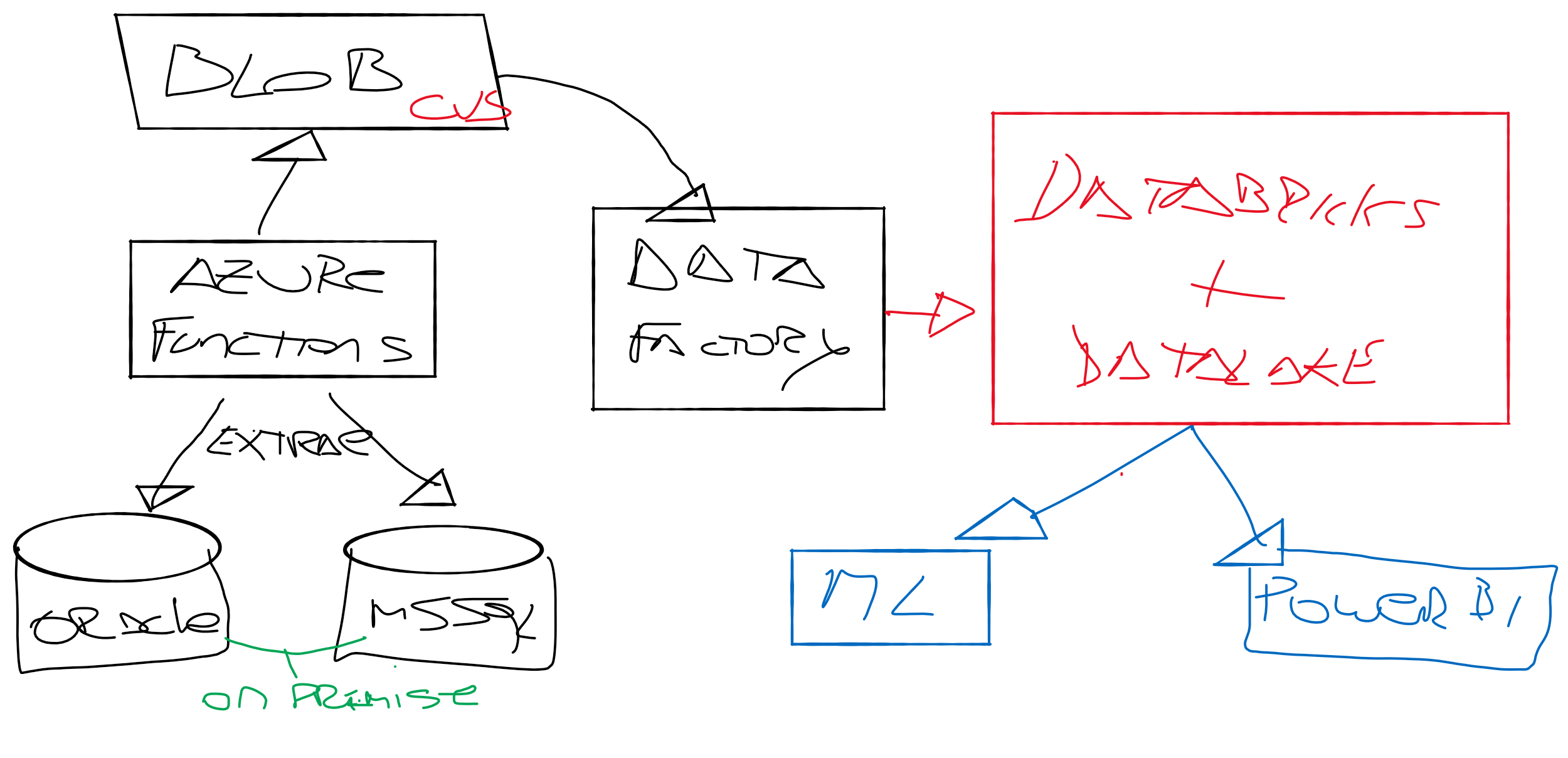
Implementación
Lo primero que hicimos fue eliminar los procesos de ETL que corrían hoy con SSIS, y la base intermedia desde donde conectaban la herramienta de BI.
Posterior a eso, realizamos el desarrollo de código Python que se ejecuta sobre Azure Functions para tomar los CVS y Parquet de proveedores, extraer la información y llevarla a Data Lake Storage.
Otra parte corre en Azure Data Factory, un integrador de datos con conectores pre-compilados que nos servían para tomar la info desde las bases relacionales y llevar los datos de manera automatizada, simplificando mucho la extracción de la info y el movimiento hacia Azure Data Lake Storage donde almacenamos lo que llegaba. A eso le sumamos Azure #DataBricks donde corremos la preparación de los datos.
Databricks es una herramienta de Azure basada en #Apache #Spark que permite configurar de manera simple flujos de trabajo optimizados, dejando la data lista para que DBA, Data Scientist o incluso Analistas de Negocios, dispongan de la información para sus labores.
Finalmente toda la capa de visualización fue armada en PowerBI, desde donde concentrábamos reportes según el perfil del usuario visualizador.
Toda la solución lógicamente tiene componentes de seguridad, como Active Directory para la autenticación.
Entre el assessment, la planificación, y ejecución del proyecto fueron 5 semanas de trabajo donde obtuvimos como resultado un producto de analítica casi en tiempo real, con un costo de menos de 500 USD mensuales pero que generaba insights claros de negocios donde antes no existían.
Los resultados fueron excelentes porque dieron visibilidad de operaciones comerciales desconocidas. Esta buena recolección de resultados mostraron un ROI muy interesante que motivó avanzar en el proyecto a una Fase 2, que consistió en generar experimentos de Machine Learning organizados desde Databricks y que nos permitieron identificar los modelos con mejor rendimiento respecto al esquema de precios de la compañía.
La combinación de Azure Databricks y Azure Machine Learning nos permitieron generar un ciclo de vida de ML orientado a predecir compras, comportamientos de clientes, y generar una adaptación del esquema de pricing que significó un aumento en las ventas de la empresa.
| [popup_anything id=”2076″] |