Como continuidad del post de MLOPS, queremos mencionar sobre PCS.
En simples palabras podemos afirmar que PCS es un framework de Data Science, creado por Bin Yua y Karl Kumbiera, del Departamento de Estadísticas de Berkeley. Es una especie de MLOPS con sustentos científicos.
Las siglas #PCS vienen de #predictability, #computability, y #stability (#predictibilidad, #computabilidad y #estabilidad).
Pero veamos de que sirve PCS.
¿Cuál es el objetivo de PCS?
Este framework esta compuesto por un flujo de trabajo denominado DSLC (data science lifecycle) que busca proporcionar resultados responsables, confiables, reproducibles y transparentes en todo el ciclo de vida de la ciencia de datos.
PCS busca generar una metodología para el correcto abordaje de proyectos de data science, teniendo en cuenta como abordar un nuevo requerimiento, como recabar la informacion, como procesarla y lógicamente, como hacer de esa data informacion de valor.
Como analistas de datos, podemos encontrarnos con proyectos disimiles. Desde analítica de cadenas proteicas, hasta fraude bancario. Detección temprana de cáncer hasta aumento de venta en e-commerce. Exploración petrolera hasta detección de spam. En fin, podemos analizar cualquier cosa.
Cuando involucramos la matemática en nuestros análisis todo se transforma en Ciencia de Datos, y es por eso que PCS es una buena base para lograr estandarizar procesos tanto para analizar datos financieros, como imágenes, o voz u otros.
¿Cómo funciona PCS?
El flujo de trabajo de PCS utiliza la predictibilidad como una verificación de la realidad y considera la importancia de la computación en la recopilación / almacenamiento de datos y el diseño de algoritmos.
De esta manera aumenta la previsibilidad y la computabilidad con un principio de estabilidad general para el ciclo de vida de la ciencia de datos.
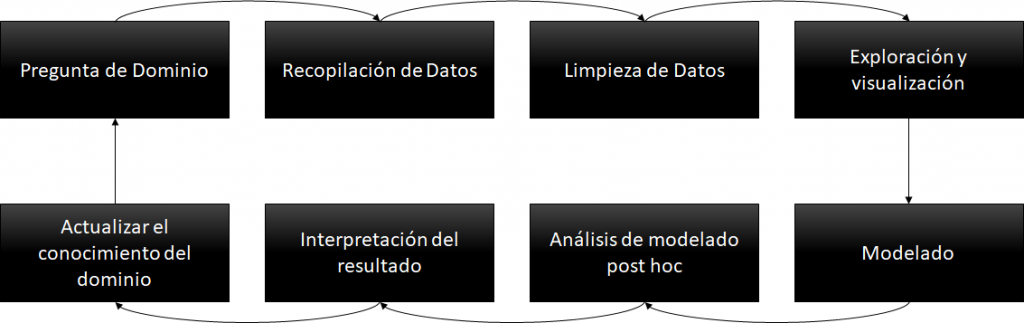
El ciclo de ciencia de datos, contiene 8 pasos concatenados que nacen desde un requerimiento (pregunta de dominio), y continua con un #pipeline basado en la recopilación de datos desde los orígenes de datos (bases de datos, redes sociales, imágenes, audios, etc), la limpieza y procesamiento de esa data recolectada, la exploración, y el modelado.
El tipo de modelado va a depender del tipo de dato que tengamos, la frecuencia, su calidad, etc.
Podemos pensar en un modelado habitual en #datawarehouse o en un modelo mas ligado a un #datalake. Posteriormente a esto se efectuaran los análisis sobre esos modelos, se interpretaran los resultados y finalmente se actualizaran los conocimientos.
La estabilidad amplía las consideraciones de incertidumbre estadística para evaluar cómo las llamadas del juicio humano impactan los resultados de los datos a través de las perturbaciones de los datos y del modelo / algoritmo.
Además, esta metodología considera procedimientos de inferencia que se basan en PCS, a saber, intervalos de perturbación de PCS y pruebas de hipótesis de PCS, para investigar la estabilidad de los resultados de los datos en relación con la formulación de problemas, limpieza de datos, decisiones de modelado e interpretaciones.
Ejemplo de un Caso de Uso
Guiados por el pipeline del grafico, vamos a simular una situación real, para hacer feliz a un gerente comercial:

- Pregunta de Dominio: un responsable comercial de una fabrica de Sommiers quiere conocer que cadena de retail es la que mas productos vende y cual será la que mayor proyección de ventas tendrá el próximo año.
- Recopilación de Datos: con herramientas de orquestación vamos a buscar datos provenientes de sistemas de ventas, finanzas, logística y también de las redes sociales.
- Limpieza: vamos a acomodar los datos de manera de poder ver la informacion para pasar al siguiente punto.
- Explorar los datos: visualizar los datos desde distintos ángulos para determinar que tengamos info de ventas, facturación, entregas, y campañas de marketing.
- Modelado: con toda la informacion recolectada y luego de confiabilizarla, vamos a modelar nuestra fuente de procesamiento de datos que fue nutrida por los pasos anteriores.
- Análisis Post Modelado: desde este nuevo origen de datos vamos a generar nuevos análisis, con mayores capacidades, corriendo análisis con algoritmos de Predicción de Ventas, Fidelización de Clientes usando Machine Learning.
- Interpretación: los algoritmos nos van a dar 2 tipos de resultados. Por un lado su performance, con lo que vamos a determinar si la informacion que tenemos es adecuada, o si necesitamos mas o mejor data. Y por otro lado en caso de que el algoritmo tenga buena performance vamos a lograr nuevos insights de negocios. Por ejemplo, determinar que una cadena de retail fue el que mas vendió durante el año en curso, pero que por sus campañas en redes sociales y el crecimiento YoY otra cadena será la que mas venda el año entrante.
- Actualizar conocimientos: Con esos outputs, vamos a poder tener nuevos insights que alimenten una nueva estrategia comercial, a partir de lo cual podemos ofrecer descuentos, u otros incentivos a la cadena de retail que creemos que será nuestro mejor socio.
Conclusiones
En este artículo, se unifican tres principios de la ciencia de datos: predictibilidad, computabilidad y estabilidad.
En resumen, este nuevo marco conceptual y práctico para formular procedimientos basados en ciencia de datos, recolectando y procesando informacion, y mostrando resultados valiosos de cara al negocio.
Queres bajarte el paper original de la universidad de Berkeley:
| [popup_anything id=”2076″] |