Introducción
En el mundo de la analítica de datos, elegir la plataforma de almacenamiento y procesamiento correcta es crucial para el éxito de cualquier proyecto. Con una variedad de opciones disponibles, Snowflake, Redshift y BigQuery se destacan como líderes en el espacio de almacenamiento de datos en la nube. Este documento compara estas tres plataformas para ayudar a entender sus diferencias, fortalezas y cómo se comparan en varios aspectos clave.
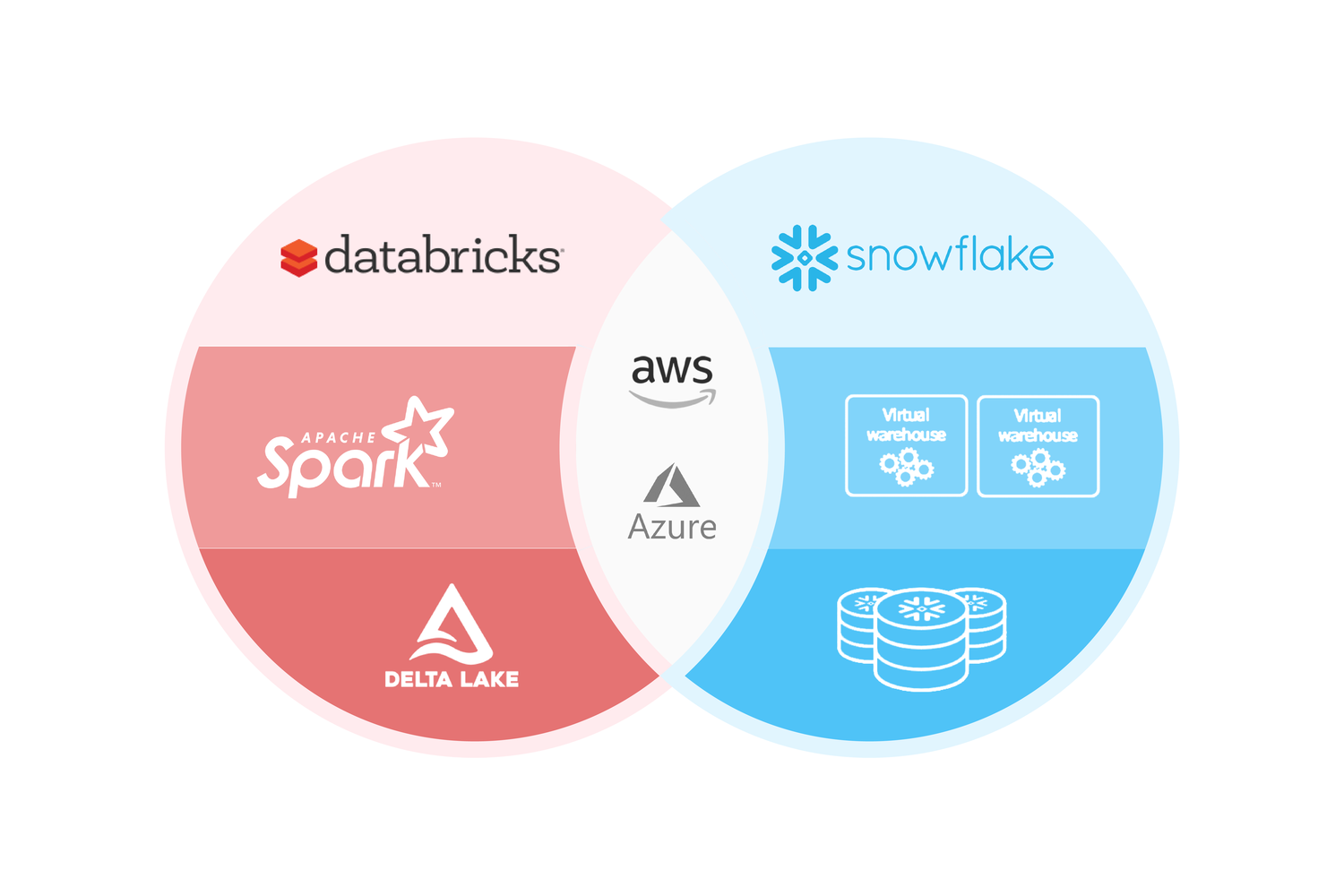
Snowflake
Snowflake ofrece una solución de almacenamiento de datos en la nube que separa el almacenamiento del cálculo, permitiendo una escalabilidad y eficiencia sin precedentes. Su arquitectura única basada en el almacenamiento de objetos y el procesamiento paralelo masivo (MPP) permite a #Snowflake manejar grandes volúmenes de datos con rapidez. Otras características destacadas incluyen el soporte para datos semiestructurados, la capacidad de realizar viajes en el tiempo en los datos y la clonación de datos sin la necesidad de duplicar los datos físicamente.
Fortalezas
- Separación del almacenamiento y cómputo para una escalabilidad eficaz.
- Soporte integrado para datos semiestructurados.
- Funciones de viaje en el tiempo y clonación de datos.
Redshift
Redshift de Amazon es un almacén de datos en la nube que utiliza una arquitectura de procesamiento paralelo masivo para proporcionar un rendimiento rápido en operaciones de petabytes de datos. Construido sobre la base de #PostgreSQL, #Redshift ha optimizado varios aspectos de su sistema para el procesamiento analítico, incluyendo una arquitectura de almacenamiento en columnas y técnicas avanzadas de compresión de datos.
Fortalezas:
- Rendimiento optimizado para grandes volúmenes de datos.
- Integración profunda con el ecosistema de #AWS.
- Funcionalidades avanzadas de optimización de consultas y gestión del rendimiento.
BigQuery
BigQuery, la solución de Google, es un almacén de datos sin servidor y totalmente gestionado que permite el análisis de grandes conjuntos de datos. Su capacidad de ejecución de consultas en tiempo real y su arquitectura sin servidor hacen de #BigQuery una opción poderosa para el análisis de datos a gran escala. BigQuery también soporta el análisis de datos semiestructurados y ofrece una integración fluida con herramientas de aprendizaje automático.
Fortalezas:
- Arquitectura sin servidor para una gestión mínima.
- Ejecución de consultas en tiempo real a gran escala.
- Integración con herramientas de aprendizaje automático de Google.
Comparativa
| Característica | Snowflake | Redshift | BigQuery |
|---|---|---|---|
| Arquitectura | Separación de almacenamiento y cómputo | Procesamiento paralelo masivo | Sin servidor |
| Datos Semiestructurados | Soporte nativo | Soporte a través de Redshift Spectrum | Soporte nativo |
| Escalabilidad | Elástica, independiente para almacenamiento y cómputo | Basada en nodos, escala junto con almacenamiento y cómputo | Automática, gestionada por Google |
| Modelado de Datos | Viajes en el tiempo y clonación | Optimización de consultas, técnicas avanzadas de compresión | Integración con aprendizaje automático, análisis en tiempo real |
| Integración Ecosistema | Amplia, con herramientas de terceros | Profunda, con servicios de AWS | Fuerte, con herramientas de Google y terceros |
 Conclusión
Conclusión
Elegir entre Snowflake, Redshift y BigQuery depende de las necesidades específicas del proyecto, el ecosistema de herramientas existente, y los requisitos de escalabilidad y gestión. Mientras que Snowflake ofrece flexibilidad con su separación de almacenamiento y cómputo, permitiendo a las organizaciones escalar de manera eficiente sus recursos según sea necesario, Redshift se destaca en el rendimiento y la integración profunda con el ecosistema de AWS, lo que puede ser un factor decisivo para las empresas que ya están profundamente integradas con otros servicios de AWS. Por otro lado, BigQuery ofrece una solución sin servidor que elimina la necesidad de gestionar la infraestructura subyacente, facilitando a las empresas el análisis de grandes conjuntos de datos con mínima gestión y configuración.
Cada plataforma tiene sus propias fortalezas y características únicas que las hacen adecuadas para diferentes tipos de cargas de trabajo y requisitos empresariales. La elección final debería basarse en una evaluación cuidadosa de estos factores en el contexto de los objetivos y necesidades específicos de la organización.