La adopción de soluciones de datos en la nube ha estado en aumento en los últimos años y dos de las principales opciones son Databricks y Snowflake. Ambas ofrecen servicios en la nube, de hecho pueden ser instaladas tanto en AWS como en Azure. Pero cada una tiene sus propias fortalezas y debilidades. En este artículo, se comparan ambas plataformas en términos de su arquitectura, capacidad de procesamiento y herramientas de análisis.
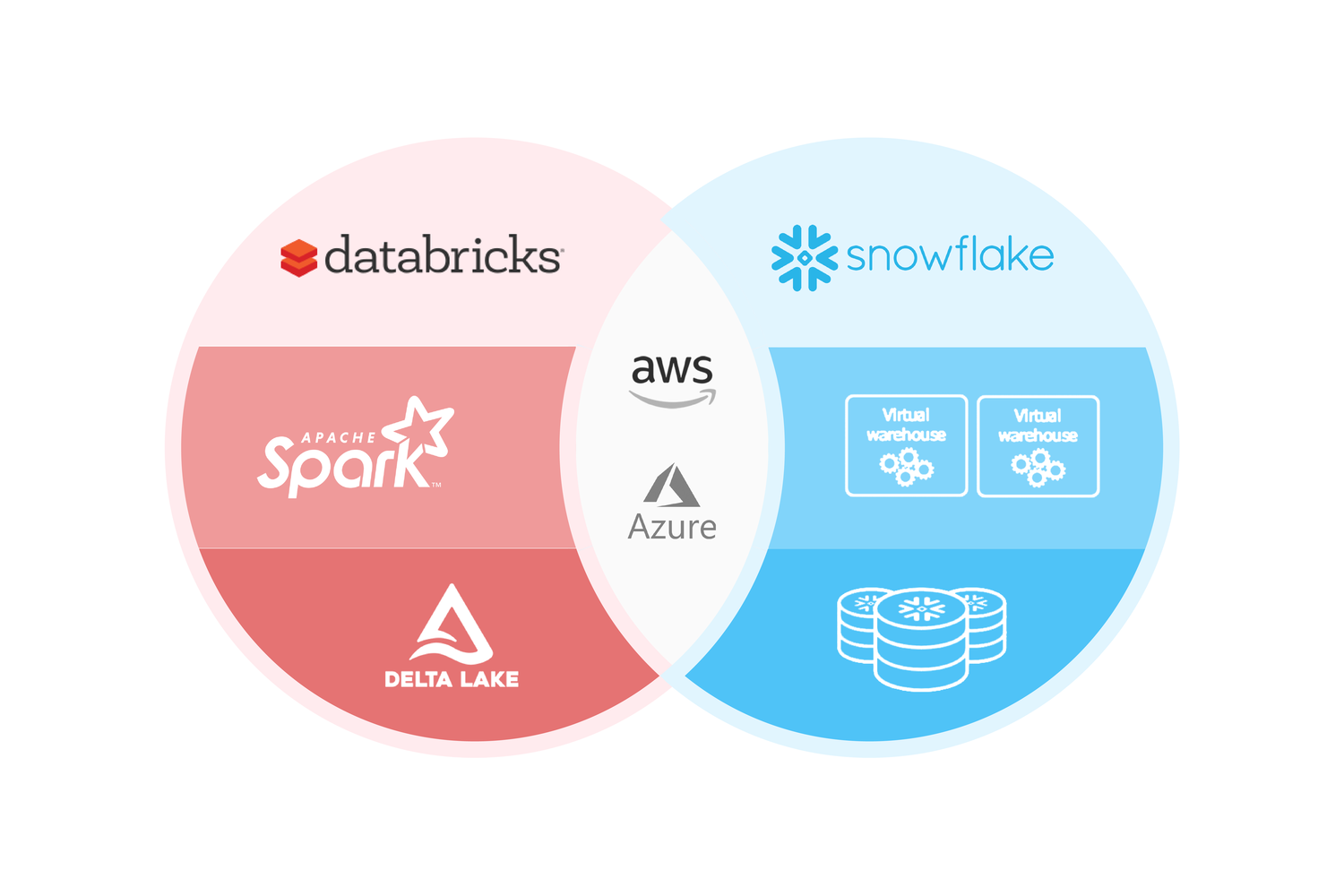
Ambas plataformas son muy eficientes en el procesamiento y análisis de datos a gran escala, pero tienen diferencias significativas en cuanto a su funcionalidad y enfoque. #Databricks se enfoca en el procesamiento de datos y el análisis de datos en tiempo real, mientras que #Snowflake se centra en la gestión de datos y el almacenamiento de datos en la nube. Ambas plataformas son muy utilizadas en la industria y son una buena opción para cualquier empresa que busque procesar y analizar grandes cantidades de datos.

Veamos algunos puntos particulares. Empecemos con:
Arquitectura
Databricks se basa en Apache Spark y tiene una arquitectura abierta y flexible que permite a los usuarios integrar diversas fuentes de datos y herramientas de análisis. También tiene integración nativa con Microsoft Azure y Amazon Web Services (AWS).
Snowflake utiliza un enfoque basado en la nube y se centra en el almacenamiento de datos. Tiene una arquitectura de tres capas y utiliza una base de datos columnar.
Capacidad de procesamiento
Databricks tiene la capacidad de procesar grandes volúmenes de datos y realizar tareas de procesamiento en paralelo en múltiples nodos. Además, su capacidad de procesamiento se puede escalar según sea necesario para manejar grandes cargas de trabajo.
Snowflake también puede procesar grandes cantidades de datos, pero se enfoca en la velocidad y la eficiencia. Además, su arquitectura basada en la nube permite a los usuarios escalar fácilmente el procesamiento según sea necesario.
Herramientas de análisis
Databricks tiene una variedad de herramientas de análisis, incluyendo librerías de ciencia de datos y herramientas de visualización. También tiene integración con herramientas de terceros, como Tableau y Power BI.
Snowflake se centra en el almacenamiento de datos y la consulta de datos. Tiene una interfaz de usuario sencilla que permite a los usuarios consultar los datos y crear informes.
Finalizando, nos llama mucho la atención que Snowflake y Databricks, dos empresas que inicialmente tenían objetivos muy diferentes, han estado compitiendo en un mercado cada vez más convergente. Snowflake se enfocó en equipos de BI mientras que Databricks se enfocó en equipos de ciencia de datos, pero ahora ambos están expandiéndose a los dominios del otro, creando una verdadera batalla por la “Plataforma de Datos en la Nube”. La propiedad de los datos es esencial en esta competencia, y ambas empresas comenzaron con sistemas de almacenamiento cerrados. Pero, para sorpresa de muchos, Databricks sorprendió a Snowflake al abrir partes de Delta Lake, lo que provocó que Snowflake siguiera el ejemplo adoptando Apache Iceberg. En respuesta, Databricks tomó medidas drásticas y donó todo Delta Lake a la Fundación Linux con el lanzamiento de Delta Lake 2.0, dejando en claro su compromiso con un estándar abierto para el almacenamiento de datos.
Ambas plataformas ofrecen soluciones de datos en la nube y tienen sus propias fortalezas y debilidades. Databricks es ideal para usuarios que requieren una plataforma de análisis de datos altamente personalizable, mientras que Snowflake es ideal para usuarios que necesitan una plataforma de almacenamiento de datos rápida y eficiente.
Alternativas a estas plataformas
Existen varias alternativas a Snowflake y Databricks en el mercado, dependiendo de las necesidades y requisitos de la empresa. Algunas de estas alternativas incluyen:
- Almacenes de datos en la nube: otras opciones populares incluyen Amazon #Redshift, Google #BigQuery, Microsoft Azure #Synapse Analytics y #Oracle Autonomous Data Warehouse.
- Plataformas de análisis unificado: hay varias opciones, como Google Cloud Dataproc, Apache Flink, Apache Beam y Apache Storm.
- Plataformas de ciencia de datos: algunas opciones incluyen Google Cloud AI Platform, Microsoft Azure Machine Learning, IBM Watson Studio y Amazon SageMaker.
Cada una de estas opciones tiene sus propias ventajas y desventajas, y la elección dependerá de los requisitos específicos de la empresa. Es importante hacer una investigación exhaustiva y evaluar las diferentes opciones antes de tomar una decisión.
Si estás buscando alternativas a Snowflake y Databricks para la gestión de tus datos en la nube, te recomendamos considerar Redshift de #AWS y Synapse de #Azure. Ambas plataformas ofrecen soluciones de almacenamiento y procesamiento de datos escalables y seguras.
AWS se destaca por su proceso constante de innovación y la incorporación de nuevas funciones y aplicaciones a su ecosistema de datos. Con Redshift, los usuarios pueden almacenar y analizar grandes cantidades de datos utilizando herramientas de análisis de datos de código abierto, como #SQL y #Python. Además, Redshift es altamente escalable y puede manejar desde pequeñas cargas de trabajo hasta grandes conjuntos de datos.
Por otro lado, Synapse de Azure se distingue por su simplicidad y robustez. La plataforma ofrece una amplia gama de herramientas integradas para el procesamiento de datos, desde la ingestión hasta el análisis. Además, la adopción de tecnología de Azure es fácil y rápida, lo que permite a los usuarios obtener resultados inmediatos.
#BigQuery es una solución de almacenamiento y análisis de datos en la nube altamente escalable y eficiente que se ha vuelto muy popular entre los usuarios de #GCP. Ofrece una variedad de características avanzadas, como la capacidad de analizar datos en tiempo real y la integración con otras herramientas de Google, como #DataStudio y #TensorFlow.
Sin embargo, a nosotros no nos resulta efectiva la calidad de su soporte técnico. En comparación con AWS y Microsoft, el soporte proporcionado por Google aún tiene mucho por mejorar.
En resumen, tanto Redshift de AWS como Synapse de Azure son excelentes alternativas a considerar si estás buscando una plataforma de gestión de datos en la nube segura, escalable y eficiente.
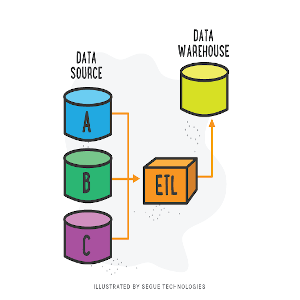

 de datos, aplicaciones empresariales y servicios web. Estos componentes se pueden personalizar y combinar para adaptarse a las necesidades específicas de cada proyecto.
de datos, aplicaciones empresariales y servicios web. Estos componentes se pueden personalizar y combinar para adaptarse a las necesidades específicas de cada proyecto.