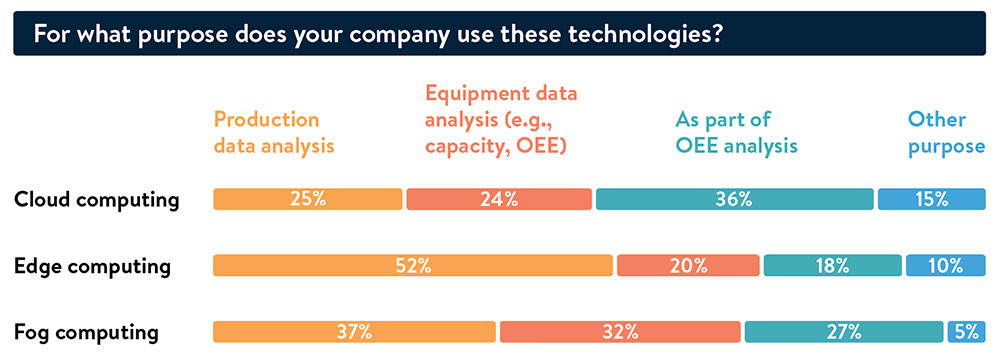
Esta nota fue publicada originalmente en Linkedin
Ya es sabido que es #DevOps. Un movimiento cultural combinado con una serie de prácticas de desarrollo de software que permiten entregar productos finales de forma rápida.
DevOps tiene pilares fundamentales como son la comunicación, responsabilidad, respeto y confianza de los miembros de un equipo.
El uso de herramientas y flujos de trabajo aptos para DevOps puede ayudar a su equipo a trabajar de una manera más DevOps “friendly”, pero es crucial crear una cultura que respalde el ideal del movimiento.
Analizando algunos ideales, entendemos que el foco está en el producto. Un equipo DevOps trabaja sobre el rendimiento del producto en todo su ciclo de vida, discutiendo los requisitos, las características, los cronogramas, los recursos y la cantidad de datos que podrían surgir, y genera objetivos conjuntos.
Esos Objetivos medibles comunes pueden ser:
- Reducir el tiempo de time-to-market.
- Aumentar la disponibilidad.
- Reducir el tiempo necesario para implementar.
- Aumentar el porcentaje de defectos detectados en #testing antes de pasar a producción.
- Hacer un uso más eficiente de la infraestructura.
- Proporcionar el rendimiento y la experiencia del usuario al gerente de producto.
Estos objetivos tienen un impacto monetario en su negocio, ya que le cuesta mas horas-hombre cuando el software tarda mas días de lo planificado en ser liberado. Le cuesta ingresos cuando el producto no está disponible para el uso de sus clientes. Aumenta su costo operativo por ejecutar su infraestructura de manera poco eficiente.
Tomando lo que sabe sobre estos valores, puede poner un valor monetario para mejorar cualquiera de ellos.
Su #stakeholder estará interesado en los objetivos mensurables que haya desarrollado.
Los objetivos nos permiten fijar metas.
Recuerde que DevOps es un nombre inapropiado: lleve DevOps más allá de los desarrolladores y las operaciones, para incluir aseguramiento de la calidad, servicio al cliente, personal comercial y liderazgo ejecutivo si es posible.
¿Necesitamos ser 100% Devops?
Tal vez no. DevOps es arriesgado para aplicaciones heredadas y organizaciones establecidas. Quizás deba mantener estos dos modos de operación separados según la aplicación. Tal vez necesitamos un sistema híbrido como el modelo definido por Garnet como IT Bimodal.
#Gartner describe a #IT-Bimodal de la siguiente manera: es la práctica de administrar dos modos separados y coherentes de entrega de TI, uno centrado en la estabilidad y el otro en la agilidad. El Modo 1 es tradicional y secuencial, haciendo hincapié en la seguridad y la precisión. El modo 2 es exploratorio y no lineal, destacando la agilidad y la velocidad. ¿Necesitamos ser 100% DevOps? Quizás no, pero de una forma u otra, se necesita hacer cambios, fundamentalmente romper con los silos y mejorar la productividad.
(Producto = Tiempo + Recursos)
Hay dos formas de aumentar la productividad. Disminuir los tiempos o aumentar los recursos.
Se alienta a los sectores de desarrollo a reducir los tiempos de desarrollo. Y se alienta a los sectores de Operaciones a mantener la productividad. Estos incentivos no son compatibles entre sí.
DevOps debería ayudar al negocio de la compañía a actuar por igual sobre los responsables del tiempo y los recursos.
El desafío para cualquier compañía es tener diferentes equipos que funcionen como uno solo.
Y en ese marco es importante gestionar el Estancamiento y Obsolescencia. Las organizaciones deben asegurarse que los sistemas de información con los que trabajan estén en un proceso continuo de actualización de los componentes. Es por ello que se debe crear un plan de obsolescencia.
La tendencia actual de IT, es tener todo definido como servicio. #IaaS, #PaaS, #SaaS. Todo será definido por el software. Los sectores de infraestructura deben superar el desafío de la transformación. El modelo de infraestructura actual está orientado a servicios y no a la granja de servidores. “El software se está comiendo el mundo”.
¿Cómo llevar un desarrollo obsoleto y estático a un modelo DevOps?
Una forma de actualizar una aplicación obsoleta es dividir las funciones en microservicios. Un microservicio debe hacer una sola cosa, pero debe hacerlo bien.
Los microservicios son simples, fáciles, pero es necesario mantenerlos estrechamente controlados y tomar precauciones para que no haya creación descontrolada de microservicios en toda la compañía.
Tener una entrega continua ayuda a las empresas a mantenerse alineadas con el objetivo de tener un producto de acuerdo con los requisitos del mercado, gracias a la reducción del tiempo de lanzamiento al mercado.
Y si algo funciona, hay que seguir mejorandolo. No importa qué tan bien funcione un sistema, siempre se puede mejorar. Mejorar y aprender nos ayuda a tener un sistema “vivo” que se adapta mejor a las demandas del negocio.
Mucho se habla acerca de Herramientas DevOps. Pero… ¿Cuáles son herramientas DevOps?
- Cualquiera que nos permita automatizar
- Cualquiera que maneje configuraciones
- Cualquiera que realice implementaciones automáticas
- Cualquiera que maneje registros
- Cualquiera que monitoree desempeño y capacidades
No existe un método de implementación de herramientas DevOps. Cada uno debe crear su propia caja de herramientas, pero debe centrarse en la automatización. Es importante lograr que cualquier tarea repetitiva sea automatizada. Automatizar aumenta las capacidades de los sistema, reduce las fallas, reduce el tiempo de ejecución y principalmente, puede medirse.
Que se puede automatizar?
- Creación de #nubes y #VM
- #Despliegues de la aplicación
- Planificación de capacidades
- Control de Intentos de acceso no permitidos
- #Backup/#Restore
- Gestión de configuración
- Gestión de #parches
- Actualizaciones de #CMDB (Y acá existe algo importante para mencionar. No importa cuán malo sea tu CMDB, necesitas tener una)
Lograr el despliegue automático tiene grandes implicancias en la reducción del time-2-market, en reducir la fricción entre desarrollo y operaciones, permite un rollback de manera rápida y disminuye en gran medida los downtimes provocados por fallas.
Para el control de funcionamiento y fallas, es necesaria una gestión inteligente de eventos ayuda a identificar problemas, errores y posibles desviaciones en el funcionamiento de un sistema. Esta informacion, junto a la medición de rendimiento nos permite medir la capacidad de los recursos para cumplir los objetivos establecidos y saber qué tan bien estamos utilizando nuestros recursos. Y junto con saber sobre la utilización de los recursos, es importante realizar la planificación de capacidades de nuestra plataforma. Conocer el uso de los recursos (y optimizarlos), proponer alternativas tecnológicas, analizar el cumplimiento de SLA, listar riesgos y principalmente aumentar la alineación entre negocios y tecnología.
DevOps nos permite aumentar el ROI. Porque? Porque en muchas casos nos permite reutilizar infraestructura o aprovechar las ventajas de plataformas más elásticas que se adaptan mejor a la estrategia de la empresa. La nube ofrece un concepto de “pago por uso”, lo que se traducido a gastos permite un ahorro en costos y convertir CAPEX en OPEX.
¿Que se puede esperar a corto plazo en materia de DevOps?
Creo que es importante llevar la conversación de DevOps más allá del ámbito técnico. Participar a la cadena de negocios completa para entregar valor de extremo a extremo. Esto incluye grupos como marketing, ventas, finanzas, legales, recursos humanos y más. Involucrar a estos grupos tan pronto como sea posible en el proceso ayudará a las organizaciones a construir mejores soluciones, al tiempo que evitarán los retrasos que se suelen generar por la burocracia del propio funcionamiento de silos verticales tradicionales.
Actualización 31/05/2019: esta nota fue publicada en #Infotechnology, mi ultima nota como #CTO de #Nubiral antes de emprender www.54cuatro.com
[popup_anything id=”2076″]