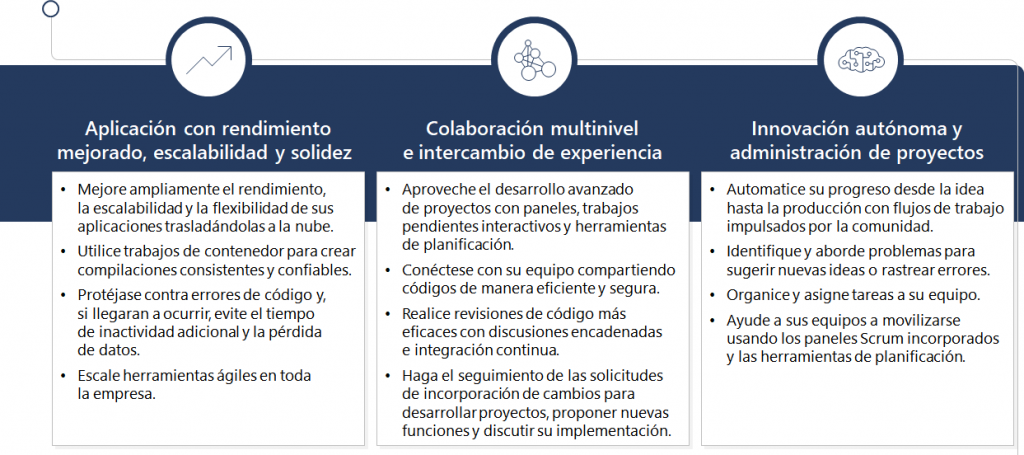
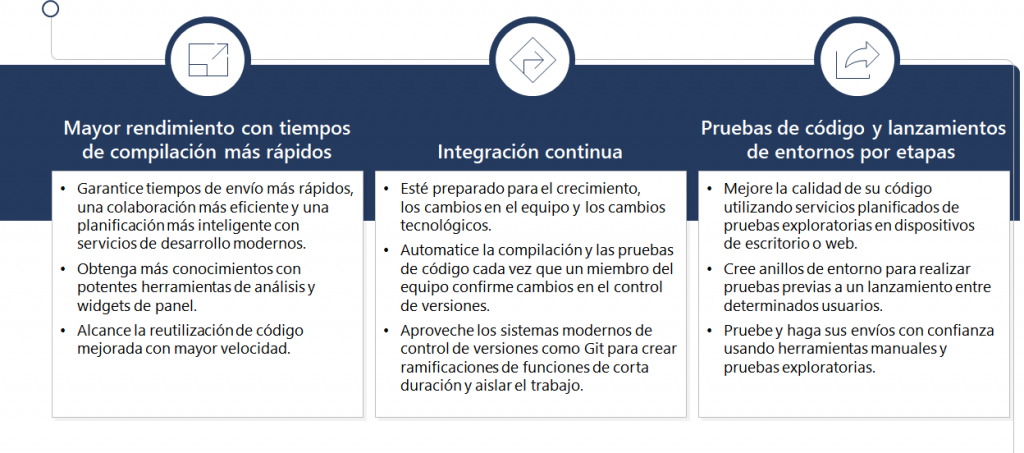
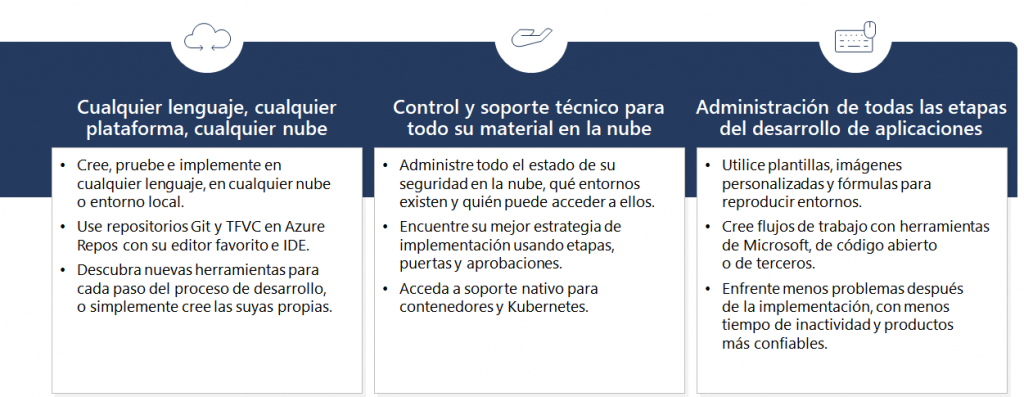
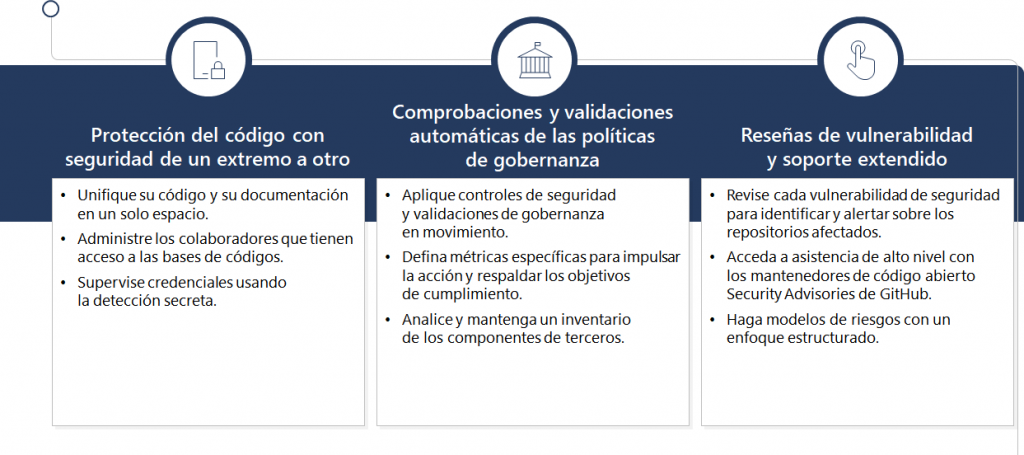
FinOps representa la gestión financiera de los servicios en la nube y es esencial para las empresas que buscan equilibrar la excelencia operativa con la eficiencia en costos. Este enfoque es particularmente crucial en organizaciones grandes y complejas, donde los costos asociados con la infraestructura en la nube pueden escalar rápidamente sin una gestión adecuada. #FinOps no solo ayuda a mantener los gastos bajo control, sino que también integra las áreas técnicas, administrativas y financieras para una gestión holística y estratégica de los recursos en la nube.
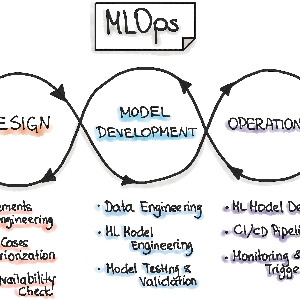
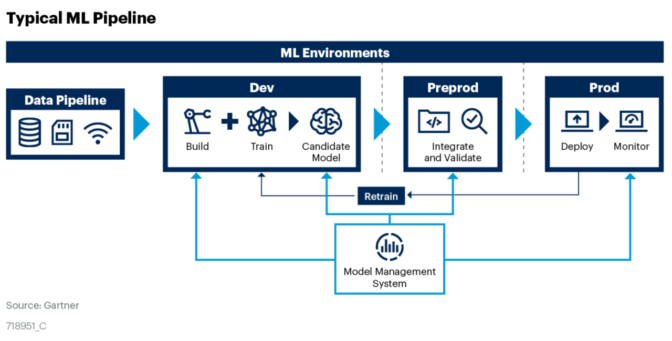
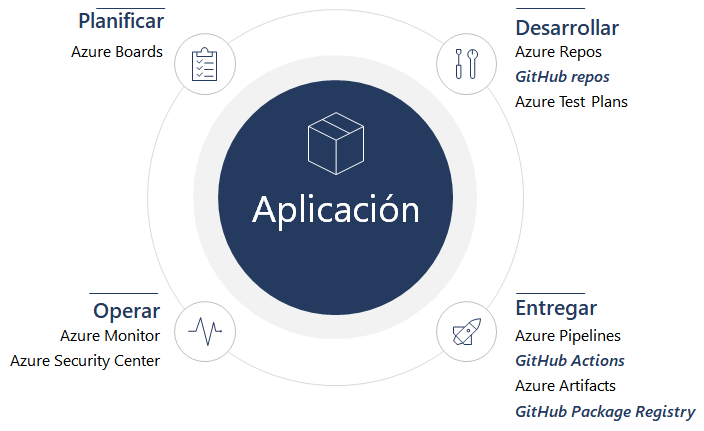
El proceso de FinOps sigue un ciclo virtuoso, similar al de #DevOps, que incluye operar la plataforma de nube, informar sobre los costos y optimizar los recursos continuamente. Este ciclo involucra a diversos actores dentro de la empresa, incluidos los equipos de ingeniería, compras, finanzas y productos. Cada uno de estos grupos desempeña un papel vital en la implementación de las estrategias de FinOps, trabajando juntos para asegurar que los recursos en la nube se utilicen de manera eficiente y económica.
Los pilares fundamentales de FinOps son varios y abarcan aspectos clave de la gestión empresarial y tecnológica:
- Colaboración entre Equipos: Promueve la cooperación en tiempo real entre los departamentos de finanzas, tecnología, productos y negocios para maximizar el rendimiento de la nube.
- Decisiones Impulsadas por Valor: Se enfoca en decisiones que equilibran costo, calidad y velocidad, subrayando el valor empresarial de cada inversión en la nube.
- Responsabilidad en el Uso de la Nube: Fomenta la descentralización del control de los costos, permitiendo que los ingenieros tomen decisiones desde el diseño hasta las operaciones.
- Datos de FinOps Accesibles y Oportunos: Asegura que la información sobre costos sea compartida rápidamente para permitir una utilización más efectiva de los recursos.
- Un Equipo Centralizado para FinOps: Un equipo dedicado que centraliza la optimización de tarifas y promueve las mejores prácticas para aprovechar las economías de escala.
- Aprovechando el Modelo de Coste Variable de la Nube: Utiliza un modelo de costo variable para adaptar los gastos a las necesidades reales, permitiendo ajustes continuos que optimizan el uso de la nube.

El impacto de una gestión ineficaz de los recursos en la nube puede ser significativo, llevando a un sobreprovisionamiento y a un gasto excesivo. Las investigaciones indican que las empresas pueden pagar hasta un 35% más en servicios en la nube debido a la falta de una estrategia de FinOps efectiva. Por otro lado, una gestión adecuada puede reducir estos costos y mejorar la eficiencia operativa.
El objetivo final de FinOps es apoyar un marco de arquitectura que combine resiliencia, seguridad y excelencia operativa con costos ajustados. Esto se logra a través de una comprensión profunda y detallada de los gastos en la nube, promoviendo la transparencia y la colaboración interdepartamental. Al alinear los gastos con el valor empresarial generado, FinOps transforma la gestión de costos en una ventaja estratégica que no solo controla los gastos, sino que también impulsa la innovación y la eficiencia en toda la organización.
En conclusión, FinOps es más que una práctica de gestión; es una filosofía empresarial que requiere una adopción integral y un compromiso a largo plazo para optimizar las inversiones en la nube y garantizar un crecimiento sostenido y rentable. Su implementación efectiva es crucial para cualquier empresa que dependa significativamente de la tecnología en la nube para sus operaciones diarias.