Si hablamos de diseño y desarrollo de #aplicaciones, Cuando mencionamos el principios #SOLID nos referimos a un acrónimo con 5 definiciones que nos ayudan a determinar los patrones de la #arquitectura y el #desarrollo de #software.
Los 5 principios SOLID
Los objetivos de estos 5 principios a la hora de escribir código son los de crear un software que cumpla con el objetivo por el cual fue creado y que sea robusto y estable. El código debe ser limpio y fácil de mantener. El código debe ser reutilizable y mantenible, de manera que puedan incorporarse cambios, nuevas funciones y mejoras de manera ágil. Los 5 principios son:
S – Single Responsibility Principle (SRP)
O – Open/Closed Principle (OCP)
L – Liskov Substitution Principle (LSP)
I – Interface Segregation Principle (ISP)
D – Dependency Inversion Principle (DIP)
Principio de Responsabilidad Única
La primera letra del acrónimo. Es el principio más importante. La responsabilidad única refiere a la definición teórica que indica que “una clase debería tener una, y solo una, razón para cambiar”, es decir que cada clase que definamos debe tener una única responsabilidad. Si nos encontramos que para agregar una nueva funcionalidad debemos modificar más de una clase o que nuestro software tiene muchas relaciones entre sus clases, evidentemente no estamos cumpliendo este principio.
Principio Abierto/Cerrado
En este principio, se entiende que una entidad de software (clase, módulo, función, etc) deberían estar abiertas para poder extenderse (lo que significa que una entidad de software debe poder adaptarse a los cambios y nuevas necesidades) y cerradas para modificarse (significa que la adaptabilidad de la entidad se da como resultado de un diseño que facilite la extensión sin modificaciones, no por modificaciones realizadas en el core de dicha entidad)
Principio de Sustitución de Liskov
En el punto 3, se da nombre a este principio gracias a Barbara Liskov, la primera ingeniera en lograr el doctorado en Ciencias de la Computación. El principio de Liskov brinda pautas para trabajar con la herencia entre clases. La principal que debe cumplir si estamos realizando la herencia de una manera correcta es que cada clase que hereda de otra puede usarse como su padre sin necesidad de conocer las diferencias entre ellas. Los objetos deben poder ser reemplazados por instancias de sus subtipos sin alterar el correcto funcionamiento del sistema.
Principio de Segregación de la Interfaz
En este método se hace hincapié, en hacer interfaces específicas, es decir, tener interfaces con pocos métodos para finalidades concretas. Las interfaces nos dan una capa de abstracción que nos ayudan a desacoplar módulos; por lo tanto la interfaz es lo que nos da el comportamiento que nuestro código espera para comunicarse con otros módulos a través de métodos y propiedades.
Principio de inversión de dependencias
Último de los principios de SOLID. En este último punto, se especifica cómo deben ser las relaciones entre componentes para evitar el acoplamiento entre los módulos de un software, lo que busca reducir las dependencias entre los módulos del código para lograr un bajo acoplamiento de las clases.
Conclusión
SOLID tiene muchos detractores que suelen indicar entre sus criticas que solo toma algunos principios muy generales para un buen diseño de software de programación orientada a objetos y luego les coloca etiquetas.
Los principios SOLID son una guía de buenas prácticas, que están relacionados entre sí de forma muy estrecha y que al aplicarlos en nuestros desarrollos facilitan la creación de un código limpio, con menor acoplamiento, más flexible, más estable y más fácil de mantener.
El fraude es una práctica efectuada ilegalmente para obtener algo a partir del engaño. El fraude esta penado por ley, y el mundo electrónico no es una excepción. Vamos a separar el #Fraude en 2. Fraude Duro y Fraude Blando.
Para poner algunos numeros sobre la mesa, el fraude Bancario mas habitual es el uso indebido de cajeros y la clonación de tarjetas. En el caso del fraude en E-Commerce lo mas habitual son las compras con tarjetas o información robada a clientes.
Tipo de Fraudes
Fraude Duro: cuando hablamos de este tipo de abuso, hablamos de engaños deliberados, donde se busca obtener un beneficio por medio del engaño. Este tipo de Fraude incluye todo tipo de eventos criminales, como por ejemplo la compra de productos con una tarjeta de crédito robada.
Fraude Blando: este tipo de actividad considera las prácticas abusivas de personas que aunque no se las considere delincuentes, pueden infringir norman y/o realizar abusos que los llevan a cometer delitos. Para poner de ejemplo de este tipo de eventos, que suelen estar ligados a reclamos excesivos, podemos mencionar la exageración y/o engaño de los daños que se presentan a las compañias de seguros.
¿Porque ocurren los fraudes?
Los fraudes suelen ocurrir ante Oportunidades que son “explotadas” o “vulneradas”. Una Oportunidad Explotada puede ser la detección de una tienda que no realiza los controles de seguridad recomendados y que permite realizar compras con una tarjeta de crédito sin validar la identidad. Una Oportunidad Vulnerada, viene de la mano de situaciones donde el atacante suele “convencer” a la victima, por ejemplo una persona que persuade a su mecánico de exagerar el reporte de daños para sacar mas dinero de la cobertura de seguros.
La transformación digital, genera un significativo aumento de los beneficios a partir de la digitalización de las operaciones de una compañía, pero también a medida que el mundo electrónico gana participación, los fraudes aumentan en cantidad y complejidad.
¿Se puede evitar?
Prácticamente todas las emrpesas se encuentran expuestas a estas situaciones, y para poder reducir el riesgo, es necesario comprender la naturaleza de por qué las personas son proclives a cometer fraude. Cuales son sus motivaciones, estrategias y herramientas, permite conocer como defenderse de sus acciones. Aquí es donde es de vital importancia contar con 2 cuestiones básicas:
Contar con datos históricos de transacciones, catalogadas para entender cuales son fraudulentas y cuales no.
Contar con conocimientos que permitan a un analista alimentar de conocimiento a un sistema maestro, con la menor cantidad de sesgos y que sea el motor de un sistema de aprendizaje automatico que cada dia tenga mejor performance.
Existe un método de trabajo Anti-Fraude, basado en 4 letras: P-D-R-D
Prevenir-Detectar-Responder-Diasuadir
Prevenir es concientizar acerca de los riesgos, tanto a personas internas como a clientes finales. Un usuario con educación financiera sabe que no debe compartir datos personales, datos financieros y mucho menos claves en un llamado telefónico. El factor cultural genera una disminución de los puntos vulnerables que los delincuentes usan en su favor.
Detectar el fraude es complejo y es donde se centran mayormente los esfuerzos. La detección es donde se invierte mayor presupuesto y esfuerzos, para detectar Transacciones Espurias, Suplantaciones de Identidad o Sistemas de Scoring. Existen diferentes sistemas antifraude con Machine Learning, que van desde la detección de transacciones electrónicas, el reconocimiento facial y cognitivo (voz/imágenes/documentos de identidad). Los sistemas de detección deben cumplir 2 condiciones:
El costo del sistema no debe ser superior al de las pérdidas.
Debe estar realizado con técnicas, como #MachineLearning, que le permita ser un sistema “vivo” que pueda ser entrenado e ir mejorando sus predicciones.
Responder significa tomar acciones inmediatas apenas detectada una situación irregular. Las respuestas esperadas al momento de la detección de un fraude son:
Avisar y tomar intervención de la situación
Recopilar datos que permitan identificar al delincuente y que sean útiles en acciones legales
Dar aviso a autoridades policiales/judiciales
Cancelar y dar “vuelta atrás” de transacciones
Generar nuevo conocimiento para el sistema de Aprendizaje para lograr mayores índices de detección en el futuro
Disuadir el fraude, esta intimamente ligado a la prevención, pero a diferencia de cuestiones genéricas, la disuación tiene que evitar el fraude a partir de eliminar aquellos factores que generan fraude, ya sea a partir de la aplicación de soluciones tecnológicas, el cambio en procesos/procedimientos o el refuerzo cultural sobre buenas prácticas.
Construyendo un sistema AntiFraude
Esquema de Deteccion de Fraude en una Base de Grafos
La aplicación de la tecnología por si sola no va a generar beneficios, si no se tiene en consideración los puntos mencionados anteriormente. Existen diferentes técnicas y estrategias para el armado de sistemas anti fraude, que requieren de la recopilación de datos, del armado de modelos de aprendizaje y algoritmos que permitan clasificar de “Fraude” / “No Fraude”. Las plataformas para procesar esta información pueden estar basadas en #BigData o sistemas de bases de datos #NoSQL; siempre dependiendo del caso de negocios.
Una gran herramienta para estas plataformas de gestión del fraude son las bases de datos NoSQL denominadas “de grafos”. Este tipo de bases permiten almacenar las relaciones entre los datos y observar esas relaciones con mucha facilidad. Esta facilidad para detectar relaciones se transforma en un gran diferencial que permite escubrir redes de fraude y otras estafas sofisticadas con un alto grado de precisión, y son capaces de detener escenarios de fraude avanzados en tiempo real.
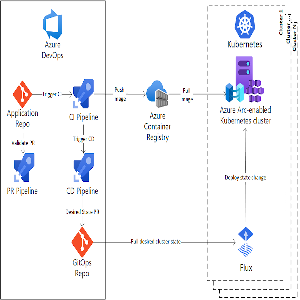
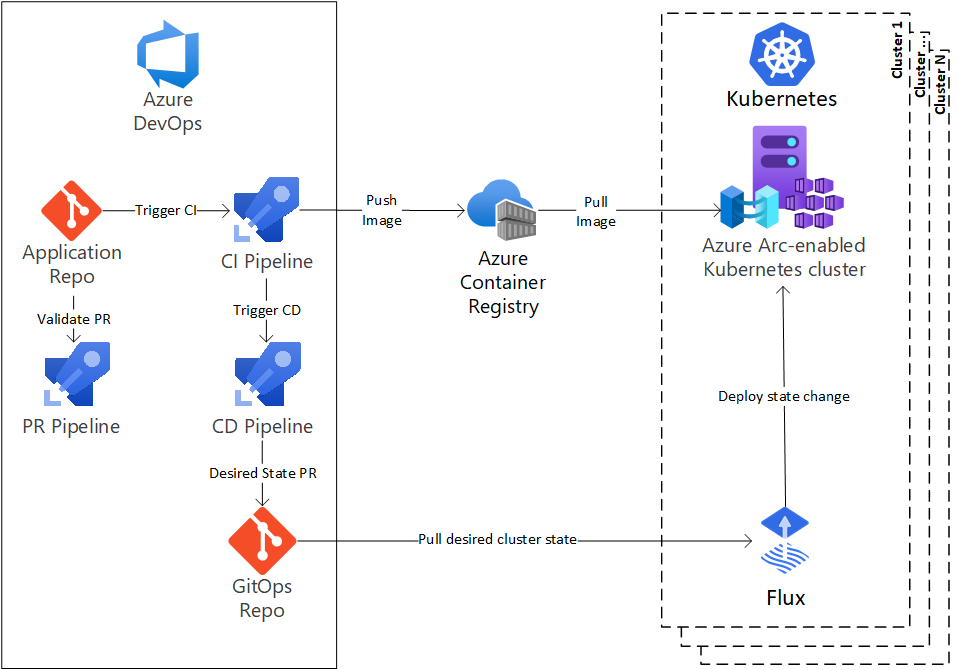
Como analizamos en notas anteriores acerca de #GitOps, es importante destacar que su adopción permite gestionar las configuraciones usando Git, y cobra vital importancia cuando hablamos de contenedores dado que se construyende forma declarativa, la configuración de las aplicaciones y sus entornos de implementación son realizadas de manera declarativas (yaml/json).
¿Porque es importante GitOps cuando hablamos de contenedores?
Recordemos que cuando desplegamos un #container basicamente pulleamos código. De esta manera, poder tener un control de versiones permite controlar los despliegues de los #contenedores, por ejemplo para recuperarse de cualquier implementación fallida.
Ademas por medio de herramientas es mucho mas transparente realizar cambios operativos, por ejemplo, solucionar un problema de producción mediante un ‘pull request’ en lugar de realizar cambios en todo el sistema productivo.
Las herramientas GitOps como ArgoCD o FluxCD permiten actuar como una fuente unica de verdad, garantizando los estados de los clusteres a partir del control de las configuraciones.
Usando CI/CD con GitOps
Estas herramientas estan monitoreando los repos con las configuraciones para detectar cambios o imágenes nuevas, de manera de desencadenar automáticamente implementaciones o cambios de configuraciones.
Estas herramientas actuan como CI/CD sin requerir de herramientas adicionales, y el despliegue se encuentra asegurado debido a que funcionan en un formato denominado “atomico y transaccional”, de manera que existen logs que garantizan que las transacciones se realicen correctamente o en caso de fallar no sean aplicados los cambios.
GitOps en la nube
El desarrollo de implementacionees en #kubernetes requiere el despliegue de aplicaciones, clusteres, entornos, etc; y los despliegues en la nube no son una excepción.
Por ese motivo, comprender como GitOps se integra con aplicaciones #cloud es importante para poder crear #pipelines CI/CD.
En el caso de #Azure, se propone la creación de una integración con la solucion #AzureDevOps.
El repositorio de aplicaciones contiene el código de la aplicación. Las plantillas de implementación de la aplicación residen en este repositorio en un formato genérico, como Helm o Kustomize. Cualquier cambio en este repo dispara el proceso de implementación.
El registro de contenedor contiene todas las imágenes propias y de terceros que se usan en los entornos de Kubernetes.
En este caso la integración esta realizada con #FluxCD, como servicio que se ejecuta en cada clúster y es responsable de mantener el estado deseado. Como mencionamos mas arriba, este servicio sondea el repositorio de GitOps en busca de cambios en su clúster y los aplica.
Dentro de este esquema propuesto por Microsoft incorporan #AzureArc, una herramienta que ofrece una administración simplificada para Windows, Linux, SQL Server y para este caso particular, los clústeres de Kubernetes. En este caso, Azure Arc sirve para los diferentes entornos necesarios para la aplicación. Por ejemplo, un único clúster puede atender a un entorno de desarrollo y QA a través de espacios de nombres diferentes.
Beneficios y Conclusión
Git es el estándar de facto de los sistemas de control de versiones y es una herramienta de desarrollo de software común para la mayoría de los desarrolladores y equipos de software. Esto facilita que los desarrolladores familiarizados con Git se conviertan en colaboradores multifuncionales y participen en GitOps. Ademas un sistema de control de versiones le permite a un equipo rastrear todas las modificaciones a la configuración de un sistema.
GitOps aporta transparencia y claridad a las necesidades de infraestructura de una organización en torno a un repositorio central ue resuelven de forma muy simple las implementaciones y los rollbacks en infraestructuras complicadas.
La visión por computadora, o #CV (Computer Vision) es un método exploratorio de imágenes por medio de la inteligencia artificial (#IA) que entrena a las computadoras para interpretar y comprender el mundo visual. Permite analizar fotos y/o vídeos con equipos tales como cámaras y que a partir de algoritmos de análisis pueden identificar y clasificar objetos que sirven para tareas tales como:
Reconocimiento de patrones/comportamientos
Procesamiento e interpretación de imágenes de video vigilancia
Análisis de imágenes multiespectrales
Modelado y reconstrucción 3D
Visión por computador en ciudades inteligentes para controles
¿Como puedo usar Azure para realizar desarrollos de Inteligencia Artificial?
#Microsoft ofrece servicios cognitivos a través de su plataforma #Azure por medio de su suite “Azure Cognitive Services“, desde donde se pueden analizar imágenes por medio de tecnología de CV, como también trabajar con Lenguaje y Voz.
Los servicios que se ofrecen tienen SDK y API disponibles. Para el caso puntual de esta nota, la parte de visión, actualmente cuenta con tres servicios:
Azure Computer Vision : para usar algoritmos de análisis de imágenes avanzados preexistentes.
Azure Custom Vision para crear, mejorar e implementar sus propios clasificadores de imágenes.
Rostro : para utilizar algoritmos faciales avanzados preexistentes para detectar y reconocer rostros humanos.
Casos Prácticos
El uso típico de las herramientas de CV se basan en enviar una imagen y obtener información detallada sobre las diversas características visuales (y atributos) que se encuentran en ella. Pero estos son algunos usos interesantes que se le puede dar a la visión por computadora:
Etiquetar características visuales: obtenga atributos que puedan servir como metadatos para la imagen.
Detectar objetos: observar imágenes/vídeos y poder detectar objetos, un caso practico podría ser detectar un automóvil mal estacionado
Detectar marcas: observar imágenes/vídeos y poder detectar marcas comerciales, esto podría ser de utilidad para una empresa que desea comparar su posicionamiento en anaqueles de un supermercado respecto a su competencia
Detectar rostros: observar imágenes/vídeos y detectar a una persona, de gran utilidad para seguridad, controles de acceso o incluso para onboarding digital. En este punto es importante destacar que Azure posee un servicio mas complejo, llamado Face Service dentro Azure Cognitive Services que permite detectar emociones, poses de la cabeza o la presencia de máscaras faciales
En caso de que lo que esté desarrollando sea muy especifico, se provee una suite llamada Custom Vision. Este módulo se centra en la creación de modelos personalizados para la detección de objetos.
Por lo general, esto requeriría un conocimiento avanzado de las técnicas de aprendizaje profundo (#deeplearning) y un gran conjunto de datos de entrenamiento, pero el uso de Custom Vision Service nos permite lograr esto con menos imágenes y sin experiencia en ciencia de datos (#datascience)
Lectura de Documentos
Otra gran funcionalidad que permite la visión por computadora, es la de reconocer textos. Como parte de la suite de Azure existe un modulo basado en #OCR (Reconocimiento óptico de caracteres) que permite leer texto impreso y escrito a mano desde imágenes y como complemento existe un servicio orientado puntualmente a la lectura de formularios llamado Form Recognizer. Esta herramienta no solo permite interpretar los datos de un formularios, sino que posibilita el procesamiento inteligente de formularios y la creación de los flujos de trabajo de automatización para documentos como recibos y facturas.
Es una herramienta de gran utilidad para la digitalización de procesos de empresas que aun dependen de la recepción de recibos de pagos de sus clientes en papel, de manera que el modelo puede reconocer formatos de los recibos, extraer los atributos (fecha y hora del pago, monto, impuestos, etc) y cargarlos en sus sistemas informáticos corporativos.
La visión por computadora es de gran utilidad para la digitialización de las compañías y organizaciones gubernamentales, ya que permiten realizar tareas repetitivas y monótonas a un ritmo más rápido y con menos errores, lo que simplifica el trabajo de los humanos.
Desde antes de la fiebre #DevOps que sabemos que había que automatizar las pruebas de software, pero no se hizo. Los equipos de desarrollo fueron haciendo mayor énfasis en las pruebas de interfaz de usuario que en pruebas unitarias, y por consiguiente se fue deformando el enfoque propuesto por Mike Cohn, denominada ‘Pirámide Ágil de Automatización de Testing’.
Agile test automation pyramid – Mike Cohn
Esta pirámide es quizás la mejor definición de como deberíamos ejecutar las pruebas, y concentrarnos en la interfaz de usuario genera un patrón basado en Detectar Errores, cuando lo que debiéramos hacer es Prevenir Errores.
Pruebas unitarias
Esto tipo de testing es el que se realiza en la etapa de desarrollo, ejecutando pruebas unitarias después de cada compilación se consiguen datos específicos para un programador; ej: hay un error y está en la línea 1143.
Además habitualmente las pruebas unitarias se realizan en el mismo lenguaje que la pieza de software de manera que los programadores suelen mantener una cierta comodidad escribiendo pruebas.
Capa de Integración
En esta capa, se suele probar la integración de todos los componentes. Es donde se controla que todos los componentes funcionen correctamente y donde se busca comprobar que la lógica del software se encuentra alineada al requerimiento. Estas pruebas no solo aplicación a arquitecturas orientadas a servicios (SOA) sino también a variantes modernas de microservicios. En el caso de pruebas de API, necesita saber cuándo fallan sus API, por qué fallaron y necesita un circuito de retroalimentación ajustado para alertarlo lo antes posible. Es importante el testing en esta capa ya que si bien el end-to-end de las aplicaciones están compuestas de varios servicios que se concatenan entre si, hay muchos casos de prueba que deben invocarse de manera individual dado que no todos pueden ser ejecutados a través de la interfaz de usuario.
Pruebas de Interfaz de Usuario
Llegamos al tope de la pirámide. Y es justamente el tope de la pirámide porque este tipo de pruebas deben realizarse lo menos posible. Por motivos varios, son costosas, difíciles de preparar y requieren mucho tiempo. Ademas de que suelen salir muchos falsos negativos y falsos positivos. Pero de todas modas no debe evitarse esta etapa, dado que probando la interfaz de usuario se logra una prueba de extremo a extremo, para verificar el sistema en su totalidad.
El equipo de desarrollo de Google sugiere que las pruebas deben ser realizadas 70% de pruebas unitarias, 20% de pruebas de integración y 10% en la capa superior.
Integrando el testing en un modelo CI/CD
Recordemos que CI/CD es un pilar de #DevOps que busca desplegar aplicaciones de software por medio de la automatización; y como es bien sabido que el #testing es parte de todo esto, debemos tener integradas las pruebas para poder seguir con el circulo virtuoso que propone DevOps.
Integrar el testing bajo el concepto de “Testing Continuo” permite detectar errores de forma temprana y por ende resolverlos con gran rapidez.
Algunos test que son potencialmente automatizables son las pruebas de regresión, funcionales, de integración y de rendimiento. Algunas herramientas nos permiten facilitar las tareas de automatización de testing, aunque no menos importante es encontrar que será automatizado, y también orquestar inteligentemente las pruebas.
Herramientas para Pruebas Continuas
#Katalon. Esta herramienta ofrece una plataforma integral para realizar pruebas automatizadas para interfaz de usuario web, servicios web, servicios API y dispositivos móviles.
#Travis CI. Travis CI es un servicio de integración continua alojado que se utiliza para crear y probar proyectos de software alojados en GitHub y Bitbucket.
#Selenium es una herramienta de prueba compatible con la mayoría de los navegadores convencionales, como Chrome, Firefox, Safari e Internet Explorer.
#Azure Test Plan. En lo que refiere a ambientes #cloud, #Microsoft tiene una gran oferta de soluciones dentro de su suite Azure DevOps, y en este caso un kit de herramientas de pruebas exploratorias y manuales con una interfaz intuitiva e integrada.
Conclusión
Este tema da para largo y en próximas entradas seguiremos explorando el testing en el marco de DevOps, haciendo foco en Microservicios, API e incluso en Data.
El testing como parte de una cadena CI/CD es muy beneficioso, pero también pueden muy desafiante. Es necesario tener un buen plan de testing tradicional antes de incorporar este procedimiento de prueba.
Posterior a tener un buen marco de pruebas es recomendable trabajar en las estrategias de incorporación del flujo de pruebas al pipeline.
La gestión de los riesgos, el cumplimiento de compliance y la auditoria es algo muy sensible en las empresas.
Algunas empresas de envergadura o incluso industrias como la banca, requieren de niveles de cumplimiento muy alto, basados en estándares internacionales y nacionales que requieren de plataformas de protección de avanzada.
En empresas medianas y chicas, la seguridad suele ser un tema trivial, hasta que surgen problemas y es donde se dan cuenta la necesidad de aseguramiento que tienen.
Verizon publicó el Data Breach Investigation Report (DBIR) 2021, donde menciona que los ataques de #Phishing y #Ransomware son las 2 amenazas mas peligrosas y que siguen en aumento.
Ademas resalta que la amenaza más significativa para las entidades gubernamentales es la de los ataques de ingeniería social, con una incidencia del 69%. En cuanto a industrias minoristas su principal amenaza es la de agentes maliciosos que ganan dinero a través del robo de datos, robo de las tarjetas de crédito y secuestro de información personal.
¿Que hacer ante las amenazas?
Gran parte de las amenazas mencionadas tienen como vector fundamental, la falta de prevención.
Desde la prevención a nivel concientización, hasta la prevención tecnológica. Dos factores claves en reducir la incidencia de ataques.
Las empresas con mucho personal o recursos distribuidos, deben fortalecer las capacitaciones de su capital humano para evitar que sean victimas de ataques de ingeniería social, donde básicamente se suele “explotar” la confianza que se logra con una persona para lograr un objetivo malicioso y donde el factor tecnológico poco puede hacer. Estos casos suelen ser:
Ceder usuarios y contraseñas
Ceder informacion personal y/o financiera
Entregar documentos y/o informacion confidencial
También existen métodos de engaño basado en la suplantación de identidad, llamado #Phishing, donde el atacante simula ser alguien que no es, en medios digitales. El ataque mas común es el envío de correos electrónicos que tienen la apariencia de proceder de fuentes de confianza (como bancos, e-commerce, retails) solicitando datos personales que al ser entregados se genera perdidas de dinero, perdida de accesos a redes sociales, etc.
Educar es el paso 1
Como dijimos, enseñar a los empleados, proveedores y personas que puedan comprometer la seguridad es un buen paso para evitar engaños y estafas.
Comenzar identificando un sitio seguro o la identidad de un email, es un buen inicio.
Asegurar es el paso 2
Las empresas tienen que tener un antivirus, un antimalware y políticas de seguridad en las computadoras. Quizás es una forma trillada, pero que en muchas casos es necesario reiterarlo porque no terminan de adoptar las medidas correctas.
Pero existe algo aun peor. Y es la necesidad de asegurar otro tipo de dispositivos, como Enlaces, Servidores de Archivos, Servidores de Impresión, y… Dispositivos Móviles!
#Android es el sistema operativo mas inseguro, el playstore de #Google suele detectar aplicaciones completamente inseguras que esconden códigos maliciosos y todos los esfuerzos parecieran ser pocos para lograr entornos seguros.
Como asegurar los entornos corporativos con herramientas Open Source
Wazuh
#Wazuh es una solución de monitoreo de seguridad gratuita, de código abierto y lista para la empresa para la detección de amenazas, monitoreo de integridad, respuesta a incidentes y cumplimiento.
Extracto de una demo con un clientee
ShiftLeft Scan
ShiftLeft Scan permite proteger código personalizado con análisis estático (SAST), bibliotecas seguras de código abierto (SCA) y emplear detección de secretos codificados y verificaciones de violación de licencia de OSS.
Snyk
Snyk encuentra, prioriza y corrige automáticamente las vulnerabilidades en las dependencias de código abierto a lo largo del proceso de desarrollo . Entre sus características se encuentran las pruebas IDE integradas durante la codificación, el escaneo nativo de Git y una puerta de seguridad CI / CD automatizada.
Hace un tiempo hicimos una entrada respecto a patrones de arquitectura para microservicios, la cual tuvo gran repercución, motivo por el cual traemos esta entrada referente a la arquitectura serverless.
Cuando hablamos de arquitectura serverless o “sin servidor” nos referimos a diseños de aplicaciones que utilizan un Backend como Servicio de terceros (ej, Auth0) o que incluyen código propio que se ejecuta en contenedores efímeros administrados por un tercero, en plataforma que denominamos “funciones como servicio” (FaaS).
Lógicamente estos contenedores son auto-administrados por el proveedor, en general Cloud Providers, pero de cara al cliente una plataforma serverless evita tener que gestionar infraestructura en su formato tradicional.
Existen aplicaciones para lograr correr Serverless on-premise, proyectos como Fission o Kubeless, permiten armar la infraestructura sobre Kubernetes; pero el gran crecimiento de estas soluciones esta dado por los proveedores como #AWS, #Azure y #GCP.
FaaS que delega un parte de la arquitectura en Backend como Servicio (#BaaS)
Este tipo de arquitectura en gran parte esta siendo impulsada por los microservicios, permitiendo generar una reduccion significativa de las ingenierias, delegando muchas partes de la arquitectura en terceros. Por ejemplo:
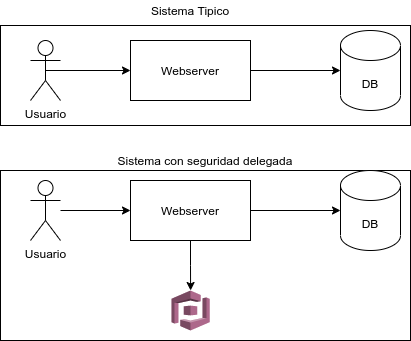
En el gráfico podemos observar un sistema típico de autorización/autenticación de un sitio web en un formato tradicional con los usuarios generados en la misma base de datos operativa, contra un sistema que delega la autorización/autenticación en un sistema de un tercero (#AWS#Cognito en el ejemplo). En el ejemplo tenemos 2 patrones. La validación de usuarios pasa a ser un microservicio, y su funcionamiento es completamente delegado a un tercero que nos brinda su backend como un servicio. En lineas generales la arquitectura de microservicios requiere de la creación de un #API gateway.
Pero sigamos avanzando y veamos otro formato de #FaaS o Serverless.
El otro formato al que se suele hacer referencia cuando se menciona #serverless se trata de ejecutar código backend sin administrar servidores y las corridas se efectúan durante un periodo de tiempo. En este caso, el código que uno realiza, es ejecutado por una plataforma de terceros, básicamente cargamos el código de nuestra función al proveedor, y el proveedor hace todo lo necesario para aprovisionar recursos, instanciar VM, crear #containers, administrar procesos, y ademas de gestionar la performance y asegurar los servicios. Las #funciones en FaaS generalmente se activan mediante tipos de eventos. Ej: recibir una petición http, detectar un objeto en un storage, tareas programadas manualmente, mensajes (tipo MQ), etc.
Precaución con el concepto de Stateless o Sin estado
Se suele decir que las FaaS son #stateless o “sin estado”. Este concepto hace referencia a que al ser código que se ejecuta de forma efímera, no existe almacenamiento disponible, de manera que cualquier función que requiera mantener persistencia debe externalizar la persistencia fuera de instancia FaaS. En Stateless cada operación se realiza como si se está haciendo por primera vez. Cuando una función requiere persistencia debemos acudir a capas adicionales de infraestructura como bases de datos de caché, bases de datos relacionales y/o storages de archivos y objetos y de esa forma pasamos a ser #stateful, lo que significa quese controla la historia de cada transacción pasada y que ellas pueden pueden afectar a la transacción actual.
Tiempo de ejecución
Otro concepto importante cuando hablamos de serverless tiene que ver con el tiempo de ejecución de las funciones. En la arquitectura sin servidor, las funciones suelen estar concatenadas y orquestadas donde cada tarea es dependiente de otra, y esto hace que si alguna se demora o falle, pueda afectar toda la sincronización configurada. Este motivo es suficiente para determinar que funciones de larga duración no son apropiadas en este modelo.
En linea con esto, existe otro concepto llamado “arranque en frío” y que tiene que ver con el nivel de respuesta de una función ante su desencadenador.
Como mencionamos, el desencadenador o trigger es lo que dispara la ejecución de una función y la función luego se ejecuta durante un periodo de tiempo determinado, esto hace que aplicaciones con muchas lineas de código, que llaman librerías, o cualquier motivo que genere que el inicio sea “pesado”, no sean recomendables para entornos FaaS.
Ventajas y Desventajas de FaaS
Sin dudas adoptar serverless es algo que esta de moda, y que trae sus grandes ventajas. En la parte de arriba hemos recorrido grandes ventajas y hemos detectado situaciones donde no es conveniente usar funciones. Pero como resumen podemos resaltar que trae grandes ventajas a nivel costos, dando como resultado una fuerte reducción de los mismos. Adicionalmente permite optimizar ejecuciones y simplificar gran parte de la administración de infraestructura requerida para ejecutar código.
En contrapartida, la arquitectura serverless requieren de cierta maduración por parte de los desarrolladores (y sus productos) ya que todo el despliegue se debe hacer bajo modelos CI/CD en lo que actualmente se esta dando a conocer como #NoOps (voy a patentar el termino YA*OPS, yet another * ops :)) donde se busca poder ir a producción sin depender de un equipo de Operaciones.
Y finalmente, es importante mencionar que al subir código a proveedores de nube se genera un alto nivel de dependencia sobre ellos, algo poco recomendado claramente.
Patrones de arquitectura
Es el titulo de la nota, pero hasta ahora no hicimos foco sobre patrones. Los patrones de arquitectura serverless aun no tiene un marco definido. Lo que se viene delimitando como mejores practicas tiene que ver con temas a considerar previo a crear una plataforma serverless. Por ejemplo:
¿Cuantas funciones se crearán?
¿Que tan grandes o pesadas serán?
¿Como se orquestarán las funciones?
¿Cuales serán los disparadores de cada función?
Gran parte de la estrategia serverless viene adoptada de las arquitecturas de microservicios y de eventos; y en gran parte los conceptos ‘Event Driven’ y ‘API Driven’ conforman el núcleo de arquitecturas serverless. Y esto hace que también debamos preguntarnos:
¿Como generamos una arquitectura híbrida que considere API, Funciones, PaaS, IaaS, etc.?
La CNCF y los proveedores de nube vienen trabajando a gran velocidad para responder estas consultas y establecer un marco arquitectónico a considerar, algo que será muy bienvenido por todos, ya que nos permitirá tener referencias por ejemplo para lograr neutralidad sobre dónde y cómo implementar nuestras apps sin caer indefectiblemente en el ‘vendor lockin’ o como generar una estrategia multicloud en arquitecturas FaaS.
Conclusión
Durante la nota explicamos ventajas, desventajas y consideraciones en cuanto a montar servicios corriendo serverless. Sin dudas es una tendencia que cada día crece mas y se encuentran nuevos beneficios. En nuestra consideración permite crear grandes productos, pero siempre hablando de productos digitales nuevos, no creemos que refactorizar aplicaciones existentes y/o migrar a serverless sea hoy una estrategia viable. No es imposible, pero si algo arriesgado. La recomendación es comenzar con piezas pequeñas, integraciones y ejecuciones controladas. Para otro tipo de aplicaciones mas complejas, los esquemas de microservicios sobre contenedores son una buena alternativa a la que incluso aun les queda mucho por recorrer.
Si esta pensando en trabajar con serverless y necesita ayuda, escribanos desde el siguiente formulario:
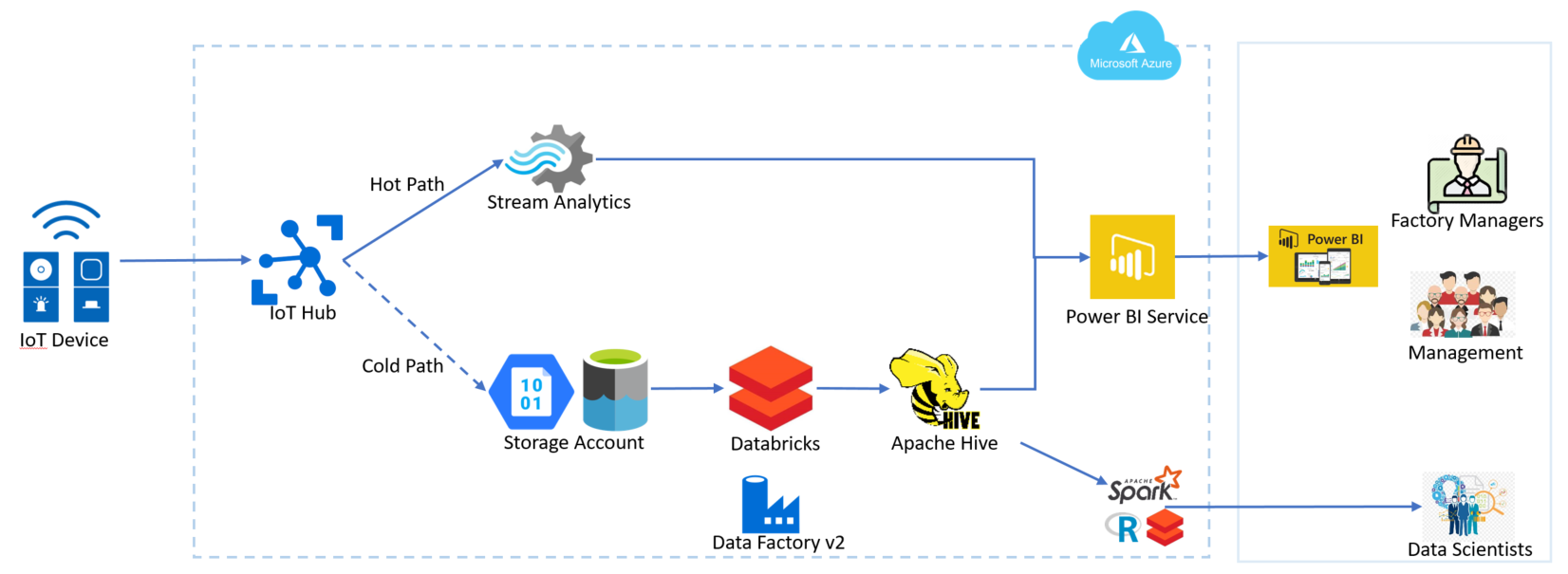
Somos partners gold de Microsoft y quizás podría parecer que esta entrada es tendenciosa, pero la realidad es que siendo imparciales, #Azure Data Factory es una herramienta increíble, quizás, de lo mejor que hay un Azure junto con #DataBricks y #Synapse para la parte de datos.
¿Que es Data Factory?
Comencemos mencionando que es una herramienta totalmente administrada, basada en proveer servicios de integración de datos y #ETL que permite orquestar el transito de datos y las transformaciones.
Como característica adicional podemos mencionar que se adapta al pequeño cambio de #ETL a #ELT para modelos de #datalakes. Recordemos que ETL significa Extraer, Transformar y Cargar, mientras que ELT significa Extraer, Cargar y Transformar. En ETL, los datos fluyen desde la fuente de datos hasta la preparación y el destino de los datos. ELT permite que el destino de los datos realice la transformación, eliminando la necesidad de almacenar los datos. En esta nota hay mas informacion al respecto.
Por otro lado, y super importante de remarcar. ADF es la herramienta que “absorbe” los paquetes de SSIS cuando se lleva una base #MSSQL de on-premise a la nube.
Veamos a detalle. ¿Que puede hacer #ADF por nosotros?
Estas son algunas características necesarias para correr ADF:
Pipelines: un pipeline es una agrupación de actividades que es realizada como un proceso integrado. En un solo pipeline se pueden ejecutar todas las acciones referidas a la manipulación de datos necesaria por un proceso.
Activities: son justamente las actividades que se corren como parte de un pipeline. Son una acción explicita, como copiar datos a una tabla de almacenamiento o transformar datos.
Dataset: los conjuntos de datos son estructuras de datos dentro de los almacenes de datos, que apuntan a los datos que las actividades necesitan utilizar como entradas o salidas.
Triggers: estos triggers o en español desencadenantes son una forma de correr una ejecución de pipeline. Los desencadenadores determinan cuándo debe comenzar la ejecución de un pipeline, de acuerdo a 3 tipos de activadores:
Programado : este activador invoca una canalización a una hora programada.
Tumbling windows trigger : este desencadenador opera en un intervalo periódico.
Basado en evento: un activador que invoca una ejecución de pipeline cuando hay un determinado evento.
Tiempo de ejecución de integración: El tiempo de ejecución de integración (IR) es la infraestructura informática que se utiliza para proporcionar capacidades de integración de datos como flujo de datos, movimiento de datos, envío de actividades y ejecución de paquetes SSIS. Hay tres tipos de tiempos de ejecución de integración disponibles, que son:
Azure, para Flujo de datos, movimiento de datos, envío de actividades
Self hosted, para Movimiento de datos, envío de actividades
SSIS, para la ejecución de paquetes #SSIS (integration services de SQL)
¿Que alternativas existen a Data Factory?
Si vamos a un esquema cloud, AWS Glue y Data Pipelines, son productos de Amazon para competir con ADF. En el aspecto #OpenSource, Apache #Kafka junto a #NiFi podrían ser un competir muy digno.
Respecto a la parte de transformación, quizás pierde un poco respecto a sus competidores, por ejemplo contra #Pentaho.
La gran ventaja de los productos 100% cloud se da por la rápida integración hacia otros productos. Por ejemplo, en el caso de una plataforma de #IoT, ADF en pocos clics se integra a Azure Event Hub. O poder trabajar integrado a Azure DevOps para poder trabajar el desarrollo de las integraciones como si fuera un software normal.
Conclusión
Este es una simple entrada para mencionar y que conozcan Azure Data Factory. Es realmente muy poderosa y su capacidad para integrarse a otras herramientas la transforma en lo que solemos llamar ‘una navaja suiza’, donde podemos tomar la informacion, procesarla, limpiarla, darle formato y enviarla a un almacenamiento destino para su uso final, ya sean tableros de BI o modelos de Machine Learning, todo como un proceso end to end.