El crecimiento de los datos se torna exponencial desde hace algunos años a hoy. Pero ese crecimiento no se ve reflejado en la utilidad que se hace de ellos, en gran medida, debido a que el porcentaje de crecimiento de datos corresponde a datos complejos de analizar.
Para simplificar esa complejidad y poder sacar valor de los datos, es que es tan importante una estrategia de Data Management.

¿Como llevar a cabo una estrategia adecuada?
Una estrategia de gestión de datos que generen valor para la organización, debe concentrarse en algunos puntos, a saber:
- Planificar que tipos de datos y pipelines va a requerir una plataforma analítica para resolver un caso de negocios
- Ser meticuloso en la gestión de la “calidad del dato”
- Crear un ciclo de vida
- Gestionar la ‘metadata’
- Cree políticas adecuadas

Estos 5 puntos son los títulos iniciales que requiere administrar como puntapié inicial de su estrategia de datos.
Vamos a ampliar cada punto para entender por que.
Planificar que tipos de datos y pipelines va a requerir una plataforma analítica para resolver un caso de negocios
Los proyectos de analítica suelen surgir siguiendo la regla ‘explorar los datos para ver que se encuentra’.
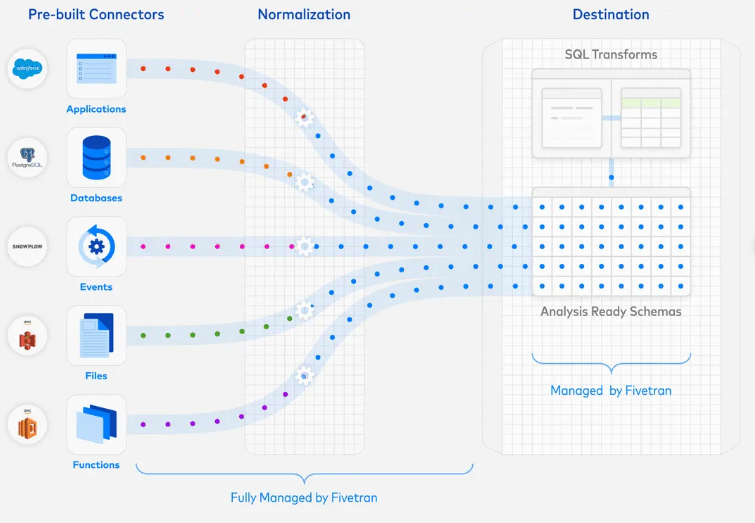
Contrariamente a este proceso habitual, los proyectos de analítica deben nacer planteando el requisito de negocios, y desde allí conseguir los datos adecuados. Esto trae como finalidad evitar 2 cuestiones. Una es encontrarse con datos sucios, evitando los procesos complejos de limpieza que se deben realizar para que tengan usabilidad. Y dos, permite considerar que datos son útiles, de dónde provienen y cómo se almacenarán.
Ser meticuloso en la gestión de la “calidad del dato”
La calidad del dato es un aspecto cada dia mas importante. La calidad (#dataquality) tiene que ver con muchas cuestiones. Datos inconsistentes, datos repetidos, info desactualizada. Hay muchas cuestiones que pueden atentar contra la calidad, pero ademas de corregir el dato en si mismo, es importante detectar porque se genera informacion de baja calidad.
¿Hay áreas en las que se producen duplicaciones de la información?
La respuesta proactiva en este caso es detectar la fuente de las inconsistencia para así aplicar reglas que corrijan ciertos procesos o acciones. Con esto vamos a lograr un aumento de la calidad.
Crear un ciclo de vida
Como analizamos en el punto anterior, para optimizar la calidad debemos establecer reglas. Y un buen proceso de creación de reglas es considerar establecer un ciclo de vida de los datos, donde podamos definir:
- Identificar el #linaje de los datos
- Establecer procesos de creación y eliminación
- Formas de almacenar
- Políticas que definan como compartirá con terceros
- Etc
El ciclo de vida es nuestra hoja de ruta para comprender la calidad y la utilidad de nuestros datos.
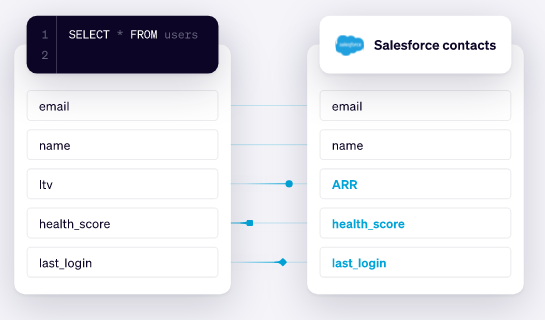
Gestionar la ‘metadata’
La #metadata es una gran amiga de los procesos de #gobernanza. Es un repositorio donde podemos contar con la informacion de como viaja la data, como se almacena, como se gestionan los cambios, etc.
Un buen plan de #governance cuenta con una gestión apropiada de los #metadatos, y principalmente se establece una identificación de los datos para asegurar la calidad, el compliance, la gestión y colaboración de nuestra info.
Cree políticas adecuadas
En el punto anterior mencionamos que la metadata permite crear una base de gestión que entre otras cosas, asegura el compliance.
Establecer políticas permite garantizar la importancia de nuestros datos, y conocer a detalle los impactos que tienen los mismos sobre la organización, gestionando el crecimiento del volumen de la informacion, su gestión y su usabilidad. Como mencionamos, el crecimiento del volumen de la info es exponencial y tener políticas adecuadas para la gestión de los mismos lo encontrara en gran forma para hacer frente a cambios, nuevas fuentes y nuevos requisitos de negocios que sean planteados.
Conclusión
Las empresas mas avanzadas en materia de gestión de datos están aplicando técnicas de #MachineLearning para su categorización y administración, pero aquellas con un poco mas de retraso, comenzar a establecer políticas de gestión de datos es un gran paso hacia la dirección de tener una estrategia integral de datos para la organización.

En este breve post quisimos mostrar aquellos hitos fundamentales en cuenta a #DataManagement, pero existen muchos mas condicionantes a tener en cuenta.
Para mayor informacion pueden contactarse con nosotros desde el siguiente formulario.


![Act. Vídeo] Webinar Actions for Industry: open banking - IEEE Sección España](https://ieeespain.org/wp-content/uploads/2020/06/Open-Banking.png)