Complementando la entrada sobre el caso de implementación de una #WebAPI que usaba Keycloak, seguimos profundizando sobre el este tema. Nuestra empresa viene trabajando con clientes en lo que hace a la digitalización de sus procesos operativos. Uno de nuestros mayores éxitos viene de la mano de una empresa dentro de la industria de Salud a la que ayudamos a actualizar su arquitectura aplicativa.
En este caso la actualización tecnológica vino de la mano de una implementación de una plataforma de gestión de identidades, donde unificar y facilitar la protección de las aplicaciones y los servicios usando una capa de AAA.
¿Qué solución planteamos?
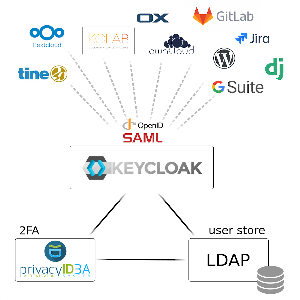
La plataforma de autenticacion estaba basada en una plataforma realizada dentro de la compañia, no contaba con protocolos de federación de identidad. A raiz de eso, planteamos el reemplazo de esa capa de autenticacion, usando una herramienta Open Source. Planteamos el uso de Keycloak, un producto de inicio de sesión único (IdP) con Identity Management y Access Management para aplicaciones y servicios modernos, 100% open source.
Adicionalmente #Keycloak permite la integración de protocolos como SAML v2 y OpenID Connect (OIDC) / OAuth2.
Objetivo logrado
Desde la vista conceptual un IdP permite que una aplicación delegue su autenticación y esto traducidos en términos empresariales facilita la protección de las aplicaciones sin tener que desarrollar nuevo código con cada aplicación, permitiendo tener un microservicio dedicado a facilitar la autenticación, robusteciendo la seguridad y acelerando el desarrollo de software.
Todas las ventajas de Keycloak:
Reducción del tiempo de entrega de software (#time2market) al dejar de preocuparse por los aspectos de seguridad de la autenticación.
Autenticación centralizada e inicio de sesión único (single sign on #SSO)
Soporte a protocolos estándar AUTH, SAML y OIDC
Integracion con LDAP y AD
Delegación de autenticación (Google, Facebook, etc)
Instalación realizada 100% sobre contenedores
Autogestión de usuarios (recovery de password, desbloqueo de cuentas)
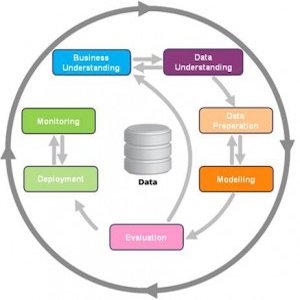
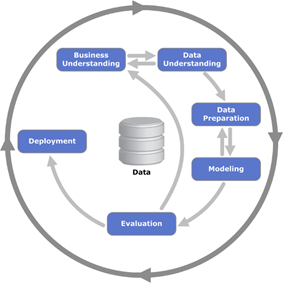
CRISP–DM es una metodología utilizada en proyectos de Data Mining. Es la guía de referencia más utilizada.
Consta de 6 fases fundamentales para encarar cualquier proyecto de Data Mining.
Comprensión de los requisitos de negocios
Comprensión de los datos disponibles
Preparación de los datos
Modelado
Evaluación
Implementación
1- Fase de Comprensión de los requisitos de negocios
En esta fase se realiza el análisis del requerimiento de negocios que buscamos resolver utilizando análisis sobre los datos.
Es una de las fases mas importantes, si no la mas importante. Establecer el objetivo permite determinar que datos necesitamos, buscar las fuentes y analizar la calidad de los datos disponibles.
El proceso de adquisición de datos es muy tedioso, dependiendo del problema que intente resolver.
2- Comprensión de los datos disponibles
Durante esta fase se identifica que datos tenemos, y como mencionamos, se analiza la calidad de esos datos.
Se busca comprender si existen faltantes fundamentales, la calidad, las relaciones, y también es donde se efectúan análisis exploratorios hipotéticos. Por ejemplo:
Seleccionar columnas importantes
Filas de muestreo (prueba de tren dividida, validación cruzada)
Crear o derivar nuevas variables compuestas
Filtrar datos (filtrar puntos de datos irrelevantes)
Fusión de fuentes de datos (agregaciones de datos)
Imputar o eliminar valor faltante
Decidir si eliminar o mantener el valor atípico
3- Preparación de los datos
En esta fase se realiza la preparación de los datos para adaptarlos a las técnicas de Data Mining que se utilicen posteriormente, tales como técnicas de visualización de datos, de búsqueda de relaciones entre variables u otras medidas para exploración de los datos.
Durante esta etapa se va a seleccionar la técnica de modelado mas apropiada, junto con la limpieza de datos, generación de variables adicionales, integración de diferentes orígenes de datos y los cambios de formato que sean necesarios.
4- Modelado
Durante el modelado, se busca establecer modelos de análisis basados en las técnicas de mining que son apropiadas al objetivo de negocios con los datos disponibles que tenemos. Si el objetivo conlleva una solución que tiene que ver con técnicas de Clasificación, podemos elegir entre Arboles de Decision, K-Near, CBR u otros. Si lo que buscamos resolver tiene que ver con Predicciones, realizaremos análisis basados en Regresiones.
Una vez determinado el modelo, se construye y adicionalmente se debe generar un procedimiento destinado a probar la calidad y validez del mismo. Por eso pasamos a la siguiente fase, Evaluación.
5- Evaluación
Durante esta fase, se realizan 2 evaluaciones. Por un lado se evalúa el modelo, teniendo en cuenta si se cumplen los objetivos de negocios planteados. Para ello se utilizan técnicas para determinar la performance de modelo, y en base a eso, ajustar las variables que mejoren su rendimiento.
Por otro lado, se evalúa que las evaluaciones realizadas por los modelos probados, son de valor para el negocio. Durante esta parte de la evaluación, es necesario trabajar con gente que pueda interpretar si los datos son fiables o es aconsejable probar otros modelos.
6- Implementación
En la fase anterior, un analista de negocio nos dio feedback sobre los resultados obtenidos. Si los datos no fueran fiables, volveríamos a fases anteriores, para ajustar el proceso. Pero si los datos dieran resultados valiosos, y es donde esta sexta fase, se considera la fase de implantación del conocimiento obtenido para que sea transformado en acciones dentro del proceso de negocio, por medio de accionables estratégicos (campañas de marketing, de ventas, publicitarias, ofertas, mejores precios, etc etc etc).
Detalles a tener en cuenta
#CRISP-DM cumple con 6 fases, las cuales no son estáticas ni estancas. Este proceso es dinamico y se debe considerar un proceso de revisión del proceso entero de #datamining, para poder identificar datos, variables, relaciones y cualquier tipo de elemento que pueda ser mejorado.
En la actualidad existen muchas ofertas de servicios basados en #MachineLearning, pero este tipo de análisis no nacieron con los servicios #cloud. Si es importante destacar que en la actualidad servicios como #Azure, #AWS y #GCP cuentan con herramientas de analítica que facilitan la recolección, limpieza y explotación de los datos, pero frameworks como #CRISP existen hace muchos años y es de vital importancia hacer uso de sus bondades, y aprovechar su ayuda para administrar los datos de una manera más estructurada.
El concepto de Logística Anticipada (“Anticipatory Package Shipping”) fue patentado por #Amazon en 2013. En líneas generales el concepto del modelo se trata de enviar un producto, que en el momento del envío no está vinculado a una dirección de entrega especificada, al centro de distribución más cercano desde donde el producto puede ser finalmente entregado al consumidor real en el futuro.
El modelo
La Logística Anticipada utiliza datos históricos de pedidos de consumidores para -predecir- pedidos futuros y, en consecuencia, enviar productos a los centros de distribución más cercanos antes de que los consumidores realicen los pedidos.
Este es un método para satisfacer las crecientes necesidades y demandas de los consumidores sobre el servicio de entrega -además de su impaciencia respecto de los plazos de entrega- y, al mismo tiempo, reducir los costos operativos.
El consumidor de hoy busca que sus compras online se correspondan con velocidades de entrega rápidas.
El modelo utiliza soluciones de big data para dar sentido a la gran cantidad de datos de compra de los consumidores, como por ejemplo los pedidos anteriores, los historiales de búsqueda de productos, las listas de deseos, el contenido del carrito de compras, las devoluciones, etc.
En este sentido, la implementación del modelo permitirá -predecir- cuando la demanda sobre un producto aumentará y por lo tanto el fabricante deberá aumentar su producción con una certeza razonable debido a la información obtenida.
En consecuencia, las empresas de logística pueden conocer con anticipación temprana las fechas posibles de entrega y calcular la cantidad de vehículos necesarios para distribuir los productos, logrando gestionar eficientemente el envío de estos a los centros de distribución más cercanos al consumidor.
Adicionalmente, el comerciante minorista, al contar con información certera, deberá aumentar su stock de productos para abastecer la futura demanda, como así también realizar diversas acciones de marketing online para generar nuevas ventas y hasta ofrecer entregas en el mismo día o incluso inmediatas.
En #SupplyChain, los modelos de Logística Anticipada junto a la implementación de dispositivos #IoT pueden ser de mucha ayuda para generar acciones de mantenimiento predictivo de las unidades de transporte, permitiendo tomar acciones anticipadas, evitar riesgos y minimizar los retrasos operacionales.
La digitalización y las nuevas fuentes de datos
Hoy las empresas no le sacan provecho a todos los datos que generan. La digitalización ha permitido el acceso a un gran número de fuentes de datos disponibles. Para escalar en el negocio, las empresas necesitan conocer y trabajar con esa información.
Utilizando la minería de datos, modelos predictivos o el aprendizaje automático se pueden generar nuevos datos y brindar información a través de tableros de control para tomar decisiones con mayor certeza, aumentando las ventas y reduciendo costos de operación.
Grandes Desafíos y Oportunidades
En el modelo de Logística Anticipada, ninguna empresa puede prever con exactitud qué ordenará realmente un consumidor en un futuro próximo con un 100% de certeza. Todo se basa en datos recopilados, historiales de búsqueda, notas y listas de deseos. Sin embargo, aquí no se incluyen compras espontáneas, cambios de deseos o excepciones. En este sentido hay una gran oportunidad para que, a través de la analítica de los datos, se pueda obtener información más certera sobre los consumidores.
Un desafío interesante es que, si bien en las áreas urbanas con centros de distribución cercanos, toda la gestión logística no parece imposible, es probable que en áreas más rurales sean más difíciles de suministrar con el modelo sin tener que calcular otras variables tanto geográficas como de densidad poblacional dentro del análisis.
Diversos estudios muestran que, el envío anticipado podría aumentar el nivel de servicio de entrega hasta un 35% y reducir los costos asociados hasta un 9,5%. Estos indicadores brindan información alentadora ya que impulsa a las empresas a implementar procesos basados en datos permitiendo mejorar la eficiencia y la calidad de servicio al predecir la demanda antes de que un consumidor haga un pedido.
Icon for electronic device authentication system, fingerprint, face scan and password input.
Este desarrollo fue diseñado para un cliente que necesitaba un sistema de #SSO para toda su plataforma de aplicaciones, algunas #API, otras #Rest y otras #SOAP. La gran mayoría de los desarrollos de nuestro cliente eran .NET.
El cliente tenia un desarrollo propio que hacia uso de autenticación y autorización, pero a través de procesos custom. La autenticación usaba usuario y password, se creaba y persistía un #customsession.
El desafio pasaba por comenzar a utilizar un protocolo standard de autorización, el elegido fue oAuth2, protocolo que utiliza #JWT pero configurando tambien SAML para casos donde hubiera necesidad de autenticar y autorizar sobre XML.
Usamos un stack tecnológico basado en Kubernetes para correr los contenedores del sistema de SSO, y Keycloak como solucion de #IAM (Identity & Access Management).
Video
Esta demo continua el desarrollo efectuado en esta entrada.
En este caso, el principal desafío era implementar una herramienta de autenticación común para todas las app de la empresa. Implementar una solución de administración de identidades tiene como objetivo mejorar la seguridad, pero al mismo tiempo se logra un aumento significativo de la productividad debido a la reducción de las tareas redundante y el re-aprovechamiento de código. Adicionalmente se genera una disminución en los costos.
Beneficios
Desde una plataforma IAM se puede lograr la administracion de usuarios internos y externos, como asi tambien las cuentas de servicios que usan las herramientas y software. Adicionalmente las apps que validan por token pueden hacerlo a traves de la misma herramienta. Es decir, tenemos una plataforma unificada que nos permite:
ABM de cuentas de usuario
Manejo de contraseñas
Inicio de sesión único (SSO)
Control de acceso basado en roles (RBAC)
Gobernanza de acceso
Auditoria y Cumplimiento
Algo destacado es que estos sistemas permiten desarrollar capacidades de autogestión que permite lograr que el usuario tenga una determinada autonomía para recuperar passwords, generar nuevos usuarios, etc.
Resumen
Como conclusión, podemos destacar que un sistema de IAM emplea la tecnología para apoyar la transformación digital. Un software que brinda facilidad de administración, un incremento importante en la seguridad, optimización de los tiempos de desarrollo y satisfacción a los clientes de la empresa.
Si necesitas ayuda, solicita asesoramiento con tu proyecto desde aqui mismo:
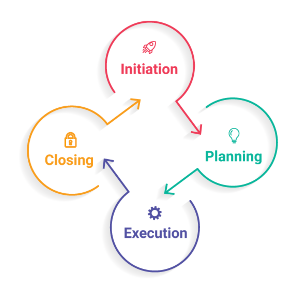
Todo #proyecto de tecnología tiene un ciclo de vida delimitado, y al margen de la metodología de gestionarlo, habitualmente el enfoque no cambia.
Empresas con metodologías waterfall o metodologías #agile, indefectiblemente pasan por algunas fases irremplazables y que conllevan mayor o menor esfuerzo.
Como mencioné anteriormente, independientemente de como gestionemos nuestros proyectos, tenemos algunas fases que impactan por igual. Enumeremos algunas de esas fases:
Definición: sin dudas el paso previo a cualquier actividad es definir el objetivo del proyecto, realizando un análisis detallado del alcance, especificaciones técnicas y financieras, roles y responsabilidades.
Planeamiento: aquí es donde podemos definir alternativas en la gestión, si lo llevaremos con una metodología #PMI o #Scrum, etc. Existe un fundamentalismo extremo en favor de Agile, pero creo que muchos proyectos bien estructurados en esquemas PMI son rotundamente exitosos. Durante la fase de Planning, es donde definiremos el presupuesto asignado, el equipo de trabajo, planificaremos fechas y definiremos entregables. Junto con todo esto, es un buen momento para el análisis de riesgos que comprometan el éxito. Hasta la improvisación debe estar planificada.
Ejecución: sin dudas esta será la fase por la que el proyecto va a ser juzgado. Durante la ejecución, comenzaremos a ejecutar todo lo analizado en las 2 fases anteriores, y cualquier error previo lo vamos a pagar con demoras. En esta fase vamos a tener que mostrar el Avance de lo planificado, los Cambios y Desviaciones que vayan surgiendo, y va a ser sin dudas la fase mas stressante para los equipos de trabajo.
Entregable: Llegado este punto, hemos logrado sortear los obstáculos y estamos listos para entregar el proyecto y laurearnos con nuestro existo. Pasado el skill transfer, la entrega de documentación, la liberación de los recursos asignados al proyecto, y porque no, el momento de la celebración, es un excelente momento para atender las “Lecciones Aprendidas”, donde vamos a generar documentos con todos aquellos condicionantes que surgieron y los cuales pudimos esquivar (o no) pero que su mera aparición nos permitieron aprender de la experiencia para no volver a cometer los mismos errores.
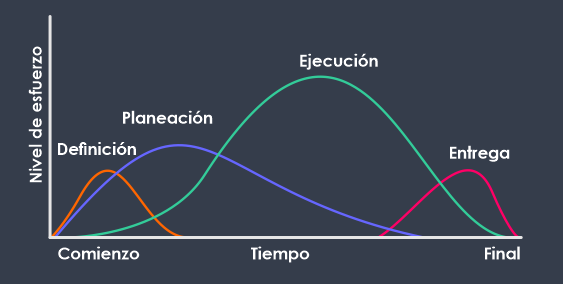
Si consideramos las 4 fases planteadas como parte de un ciclo de vida de proyectos, podemos entender el esfuerzo de cada fase según el siguiente gráfico:
Resumen
Soy un fanático de resaltar las bondades de las personas. Y voy a cerrar esta nota, diciendo que en mi experiencia, no importa tanto si la metodología era Scrum o PMI, tampoco Six Sigma o Kaizen. Mucho menos si el proyecto se lleva en Jira o en Project. Lo importante son las personas, siempre. Un proyecto donde se trabaja cada fase con responsabilidad y donde cada integrante tiene potestad, voz propia, y puede brillar con luz propia, tiene el éxito asegurado.
Como homenaje al 10, decidimos poner sus datos como jugador en estos tableros. Para verlo completo, poner “Pantalla completa” en la parte inferior del tablero.
Seguimos incrementando la informacion acerca de #MLOPS. En un primer post presentamos el concepto, y en un segundo post hablamos de PCS una metodología MLOPS made in Berkeley.
Este post esta dedicado a Cristian Cascon, un amigo de la casa, ingeniero de datos de Telecom Argentina y referente de la industria, quien nos alentó a escribir sobre los feature stores.
Gonzalo D’Angelo
MLOps es un derivado de DevOps implementado la idea de DevOps por medio de pipelines de aprendizaje automático. Ahora vamos a analizar un tema importante al momento de disponibilizar los datos a nuestros científicos de datos, los Features Stores.
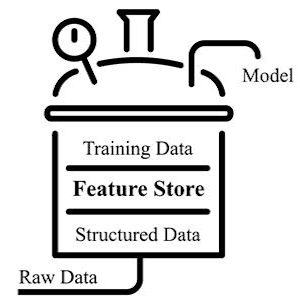
¿Que son los Feature Stores?
Un feature store es nuestro “datawarehouse” de características, nuestra unidad central de almacenamiento de funciones documentadas, seleccionadas y con control de acceso que se pueden usar en muchos modelos diferentes, es decir, una biblioteca de software que contiene muchas funciones.
Un #FeatureStore es un componente crítico para cualquier proceso de aprendizaje automático, y donde mejores features significan mejores modelos y por tanto un mejor resultado comercial. A un FS se le ingestan datos de múltiples fuentes diferentes de la empresa con procesos de transformación, agregación y validación de datos.
Todo proyecto de ciencia de datos comienza con la búsqueda de las funciones adecuadas que resuelvan el requerimiento planteado.
El problema principalmente es que no existe un lugar único para buscar; las funciones están alojadas en todas partes, eso lleva a que generar características requiera de un gran esfuerzo, y un largo proceso de prueba y error.
Entonces, podemos decir que un FS proporciona un solo panel donde compartir todas las características disponibles, y no es solo una capa de datos, también es un servicio de transformación de datos que permite a los usuarios manipular datos sin procesar.
Gracias a un FS, el pipeline de Machine Learning o #MLOPS va a simplificarse y permitirá que un #datascientist optimice sus tiempos y realice trabajos de mayor calidad.
Cuando un científico de datos inicia un nuevo proyecto, puede ir a este catálogo y encontrar fácilmente las características que busca.
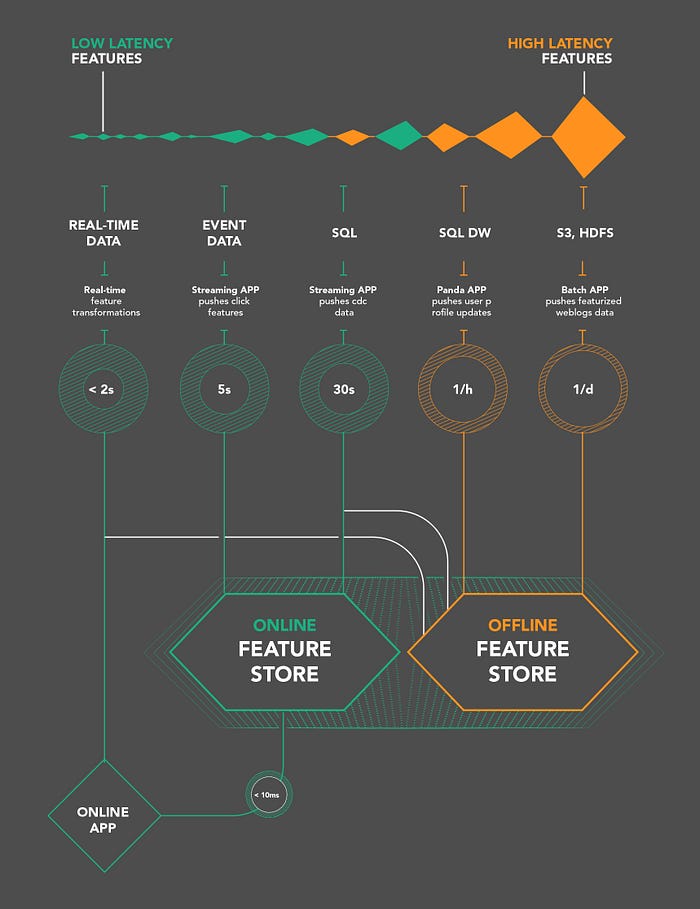
El almacén de características se implementa normalmente de 2 modos: online y offline
Funciones sin conexión: algunas funciones se calculan como parte de un trabajo por lotes. Por ejemplo, un caso de uso seria el análisis de gastos promedios. Se utilizan principalmente en procesos tipo batch. Dada su naturaleza, la creación de este tipo de funciones puede llevar tiempo. Por lo general, las características sin conexión se calculan a través de marcos como Spark o simplemente ejecutando consultas SQL en una base de datos determinada y luego utilizando un proceso de inferencia por lotes.
Funciones en línea: estas funciones son un poco más complicadas, ya que deben calcularse near-realtime y, a menudo, se ofrecen en una latencia de milisegundos. Por ejemplo, la detección de fraudes en tiempo real. En este caso, la tubería se construye calculando la media y la desviación estándar sobre una ventana deslizante en tiempo real. Estos cálculos son mucho más desafiantes y requieren un cálculo rápido, así como un acceso rápido a los datos. Los datos se pueden almacenar en memoria o en una base de datos de valores clave.
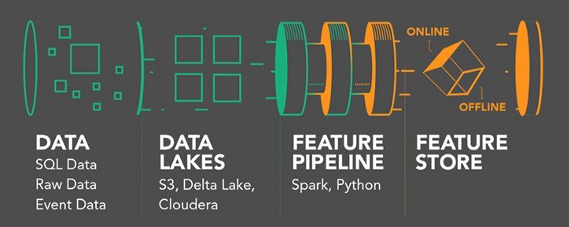
Esta imagen es excelente para diferencias ambos modos:
Imagen tomada de logicalclocks.com
Los científicos de datos están duplicando el trabajo porque no tienen una tienda de funciones centralizada. Todos con los que hablo realmente quieren construir o incluso comprar una tienda de características … si una organización tiene una tienda de características, el período de puesta en marcha [para los científicos de datos puede ser mucho más rápido].
Harish Dodi
Resumen
Los científicos de datos son uno de los principales usuarios de la Feature Stores. Usan un repositorio para realizar análisis de datos exploratorios.
Cuando los científicos de datos necesitan crear datos de entrenamiento o prueba con Python o cuando se necesitan características en línea (para entregar características a modelos en línea) con baja latencia, necesita una tienda de características. Del mismo modo, si desea detectar la derivación de features o datos, necesita soporte para calcular estadísticas de features e identificar la derivación.
Un Feature Store permite a los profesionales de datos de su empresa seguir un mismo flujo de trabajo en cualquier proyecto de #MachineLearning, independientemente de los desafíos que estén abordando (como clasificación y regresión, pronóstico de series de tiempo, etc.).
Otro beneficio es el ahorro de tiempo que genera ya que reduce el esfuerzo en el modelado donde se crean features, etapa que suele ser la mas costosa en tiempo.
El uso de un Feature Store hace que el proceso de creación de características sea mucho más ágil y eficiente, evitando trabajos repetitivos y siendo posible acceder fácilmente a una gran cantidad de datos que se necesitan para fines de modelado e investigación.
Como continuidad del post de MLOPS, queremos mencionar sobre PCS.
En simples palabras podemos afirmar que PCS es un framework de Data Science, creado por Bin Yua y Karl Kumbiera, del Departamento de Estadísticas de Berkeley. Es una especie de MLOPS con sustentos científicos.
Este framework esta compuesto por un flujo de trabajo denominado DSLC (data science lifecycle) que busca proporcionar resultados responsables, confiables, reproducibles y transparentes en todo el ciclo de vida de la ciencia de datos.
PCS busca generar una metodología para el correcto abordaje de proyectos de data science, teniendo en cuenta como abordar un nuevo requerimiento, como recabar la informacion, como procesarla y lógicamente, como hacer de esa data informacion de valor.
Como analistas de datos, podemos encontrarnos con proyectos disimiles. Desde analítica de cadenas proteicas, hasta fraude bancario. Detección temprana de cáncer hasta aumento de venta en e-commerce. Exploración petrolera hasta detección de spam. En fin, podemos analizar cualquier cosa.
Cuando involucramos la matemática en nuestros análisis todo se transforma en Ciencia de Datos, y es por eso que PCS es una buena base para lograr estandarizar procesos tanto para analizar datos financieros, como imágenes, o voz u otros.
¿Cómo funciona PCS?
El flujo de trabajo de PCS utiliza la predictibilidad como una verificación de la realidad y considera la importancia de la computación en la recopilación / almacenamiento de datos y el diseño de algoritmos.
De esta manera aumenta la previsibilidad y la computabilidad con un principio de estabilidad general para el ciclo de vida de la ciencia de datos.
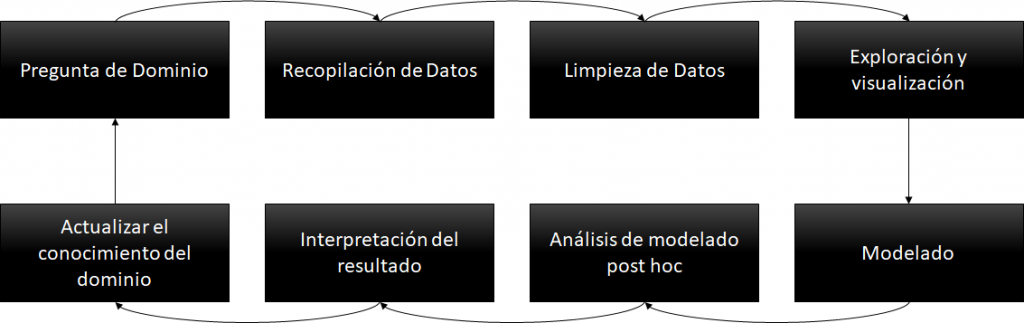
El ciclo de ciencia de datos, contiene 8 pasos concatenados que nacen desde un requerimiento (pregunta de dominio), y continua con un #pipeline basado en la recopilación de datos desde los orígenes de datos (bases de datos, redes sociales, imágenes, audios, etc), la limpieza y procesamiento de esa data recolectada, la exploración, y el modelado.
El tipo de modelado va a depender del tipo de dato que tengamos, la frecuencia, su calidad, etc.
Podemos pensar en un modelado habitual en #datawarehouse o en un modelo mas ligado a un #datalake. Posteriormente a esto se efectuaran los análisis sobre esos modelos, se interpretaran los resultados y finalmente se actualizaran los conocimientos.
Ciclo de vida de Data Science
La estabilidad amplía las consideraciones de incertidumbre estadística para evaluar cómo las llamadas del juicio humano impactan los resultados de los datos a través de las perturbaciones de los datos y del modelo / algoritmo.
Además, esta metodología considera procedimientos de inferencia que se basan en PCS, a saber, intervalos de perturbación de PCS y pruebas de hipótesis de PCS, para investigar la estabilidad de los resultados de los datos en relación con la formulación de problemas, limpieza de datos, decisiones de modelado e interpretaciones.
Ejemplo de un Caso de Uso
Guiados por el pipeline del grafico, vamos a simular una situación real, para hacer feliz a un gerente comercial:
Un gerente feliz
Pregunta de Dominio: un responsable comercial de una fabrica de Sommiers quiere conocer que cadena de retail es la que mas productos vende y cual será la que mayor proyección de ventas tendrá el próximo año.
Recopilación de Datos: con herramientas de orquestación vamos a buscar datos provenientes de sistemas de ventas, finanzas, logística y también de las redes sociales.
Limpieza: vamos a acomodar los datos de manera de poder ver la informacion para pasar al siguiente punto.
Explorar los datos: visualizar los datos desde distintos ángulos para determinar que tengamos info de ventas, facturación, entregas, y campañas de marketing.
Modelado: con toda la informacion recolectada y luego de confiabilizarla, vamos a modelar nuestra fuente de procesamiento de datos que fue nutrida por los pasos anteriores.
Análisis Post Modelado: desde este nuevo origen de datos vamos a generar nuevos análisis, con mayores capacidades, corriendo análisis con algoritmos de Predicción de Ventas, Fidelización de Clientes usando Machine Learning.
Interpretación: los algoritmos nos van a dar 2 tipos de resultados. Por un lado su performance, con lo que vamos a determinar si la informacion que tenemos es adecuada, o si necesitamos mas o mejor data. Y por otro lado en caso de que el algoritmo tenga buena performance vamos a lograr nuevos insights de negocios. Por ejemplo, determinar que una cadena de retail fue el que mas vendió durante el año en curso, pero que por sus campañas en redes sociales y el crecimiento YoY otra cadena será la que mas venda el año entrante.
Actualizar conocimientos: Con esos outputs, vamos a poder tener nuevos insights que alimenten una nueva estrategia comercial, a partir de lo cual podemos ofrecer descuentos, u otros incentivos a la cadena de retail que creemos que será nuestro mejor socio.
Conclusiones
En este artículo, se unifican tres principios de la ciencia de datos: predictibilidad, computabilidad y estabilidad. En resumen, este nuevo marco conceptual y práctico para formular procedimientos basados en ciencia de datos, recolectando y procesando informacion, y mostrando resultados valiosos de cara al negocio.
Queres bajarte el paper original de la universidad de Berkeley: