Seguimos incrementando la informacion acerca de #MLOPS. En un primer post presentamos el concepto, y en un segundo post hablamos de PCS una metodología MLOPS made in Berkeley.
Este post esta dedicado a Cristian Cascon, un amigo de la casa, ingeniero de datos de Telecom Argentina y referente de la industria, quien nos alentó a escribir sobre los feature stores.
Gonzalo D’Angelo
MLOps es un derivado de DevOps implementado la idea de DevOps por medio de pipelines de aprendizaje automático. Ahora vamos a analizar un tema importante al momento de disponibilizar los datos a nuestros científicos de datos, los Features Stores.
¿Que son los Feature Stores?
Un feature store es nuestro “datawarehouse” de características, nuestra unidad central de almacenamiento de funciones documentadas, seleccionadas y con control de acceso que se pueden usar en muchos modelos diferentes, es decir, una biblioteca de software que contiene muchas funciones.
Un #FeatureStore es un componente crítico para cualquier proceso de aprendizaje automático, y donde mejores features significan mejores modelos y por tanto un mejor resultado comercial. A un FS se le ingestan datos de múltiples fuentes diferentes de la empresa con procesos de transformación, agregación y validación de datos.
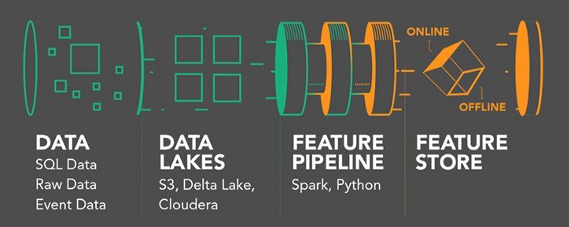
Todo proyecto de ciencia de datos comienza con la búsqueda de las funciones adecuadas que resuelvan el requerimiento planteado.
El problema principalmente es que no existe un lugar único para buscar; las funciones están alojadas en todas partes, eso lleva a que generar características requiera de un gran esfuerzo, y un largo proceso de prueba y error.
Entonces, podemos decir que un FS proporciona un solo panel donde compartir todas las características disponibles, y no es solo una capa de datos, también es un servicio de transformación de datos que permite a los usuarios manipular datos sin procesar.
Gracias a un FS, el pipeline de Machine Learning o #MLOPS va a simplificarse y permitirá que un #datascientist optimice sus tiempos y realice trabajos de mayor calidad.
Cuando un científico de datos inicia un nuevo proyecto, puede ir a este catálogo y encontrar fácilmente las características que busca.
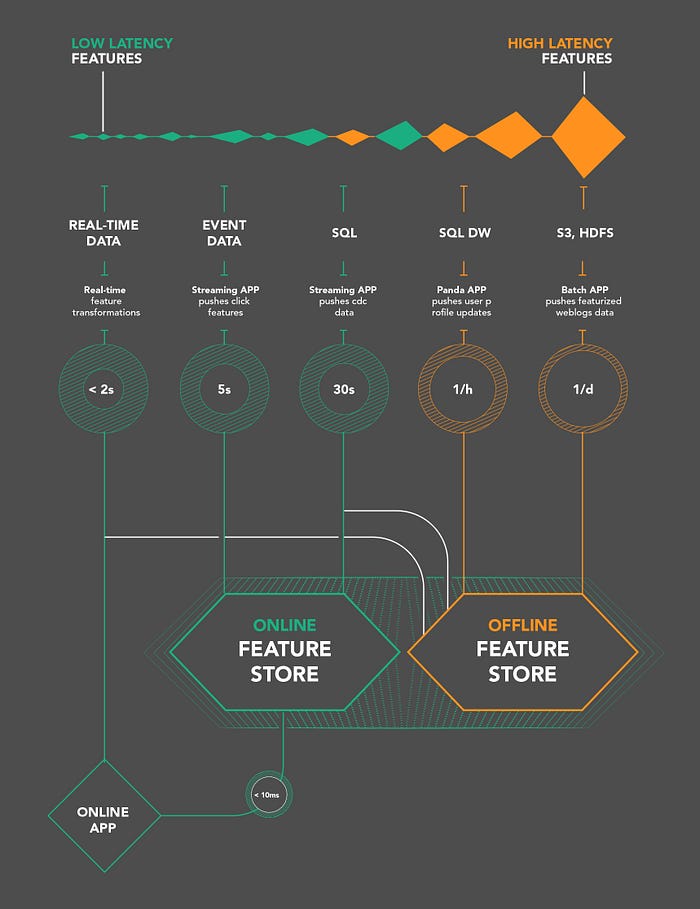
El almacén de características se implementa normalmente de 2 modos: online y offline
Funciones sin conexión: algunas funciones se calculan como parte de un trabajo por lotes. Por ejemplo, un caso de uso seria el análisis de gastos promedios. Se utilizan principalmente en procesos tipo batch. Dada su naturaleza, la creación de este tipo de funciones puede llevar tiempo. Por lo general, las características sin conexión se calculan a través de marcos como Spark o simplemente ejecutando consultas SQL en una base de datos determinada y luego utilizando un proceso de inferencia por lotes.
Funciones en línea: estas funciones son un poco más complicadas, ya que deben calcularse near-realtime y, a menudo, se ofrecen en una latencia de milisegundos. Por ejemplo, la detección de fraudes en tiempo real. En este caso, la tubería se construye calculando la media y la desviación estándar sobre una ventana deslizante en tiempo real. Estos cálculos son mucho más desafiantes y requieren un cálculo rápido, así como un acceso rápido a los datos. Los datos se pueden almacenar en memoria o en una base de datos de valores clave.
Esta imagen es excelente para diferencias ambos modos:
Los científicos de datos están duplicando el trabajo porque no tienen una tienda de funciones centralizada. Todos con los que hablo realmente quieren construir o incluso comprar una tienda de características … si una organización tiene una tienda de características, el período de puesta en marcha [para los científicos de datos puede ser mucho más rápido].
Harish Dodi
Resumen
Los científicos de datos son uno de los principales usuarios de la Feature Stores. Usan un repositorio para realizar análisis de datos exploratorios.
Cuando los científicos de datos necesitan crear datos de entrenamiento o prueba con Python o cuando se necesitan características en línea (para entregar características a modelos en línea) con baja latencia, necesita una tienda de características. Del mismo modo, si desea detectar la derivación de features o datos, necesita soporte para calcular estadísticas de features e identificar la derivación.
Un Feature Store permite a los profesionales de datos de su empresa seguir un mismo flujo de trabajo en cualquier proyecto de #MachineLearning, independientemente de los desafíos que estén abordando (como clasificación y regresión, pronóstico de series de tiempo, etc.).
Otro beneficio es el ahorro de tiempo que genera ya que reduce el esfuerzo en el modelado donde se crean features, etapa que suele ser la mas costosa en tiempo.
El uso de un Feature Store hace que el proceso de creación de características sea mucho más ágil y eficiente, evitando trabajos repetitivos y siendo posible acceder fácilmente a una gran cantidad de datos que se necesitan para fines de modelado e investigación.
| [popup_anything id=”2076″] |





